
Frequency Band Allocation in MP3 Encoding

Let’s talk about frequency band allocation in MP3 encoding
When I first learned about frequency band allocation in MP3 encoding, it reminded me of organizing items in a suitcase. The suitcase is the MP3 file, and the items are the audio frequencies. Each item—or frequency—needs just the right space to ensure everything fits while keeping what’s essential. This is the magic behind MP3 encoding. It breaks audio into smaller chunks or frequency bands, prioritizing what the human ear can hear best and discarding the rest. This ensures the file size stays manageable while preserving quality.
The MP3 format utilizes psychoacoustic models to understand which frequencies are most important. High-priority bands hold rich, detailed sounds, while less critical bands—those our ears are less sensitive to—might be reduced or eliminated. It’s like deciding to pack a sweater over a scarf when you’re short on space. This concept fundamentally transforms how we store and share music.
Understanding frequency bands in audio compression
Frequency bands in audio compression are like compartments in a toolbox. Each one serves a specific purpose, organizing the sound spectrum into manageable chunks. Low frequencies, like bass, occupy one area, while mid and high frequencies, like vocals and cymbals, take other sections.
This segmentation allows MP3 encoders to apply different levels of compression to each band. For instance, low frequencies need more data for clarity because they carry much of the song’s energy. High frequencies, on the other hand, are often less noticeable to our ears and can handle more compression. The brilliance lies in tailoring the process for each band, maintaining a balance between quality and file size.
The psychoacoustic principle and its role
The psychoacoustic principle is the science behind why MP3s sound good despite compression. When I explain it, I think about sunglasses. Sunglasses filter out harsh light while letting in the parts that help you see clearly. Similarly, MP3 encoding filters out inaudible sounds while preserving those we notice most.
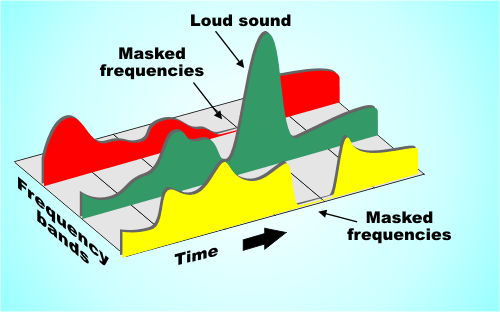
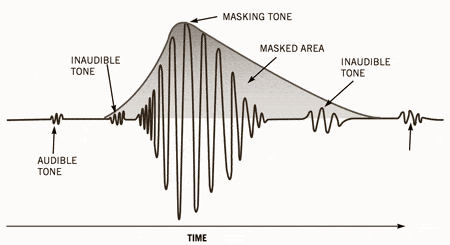
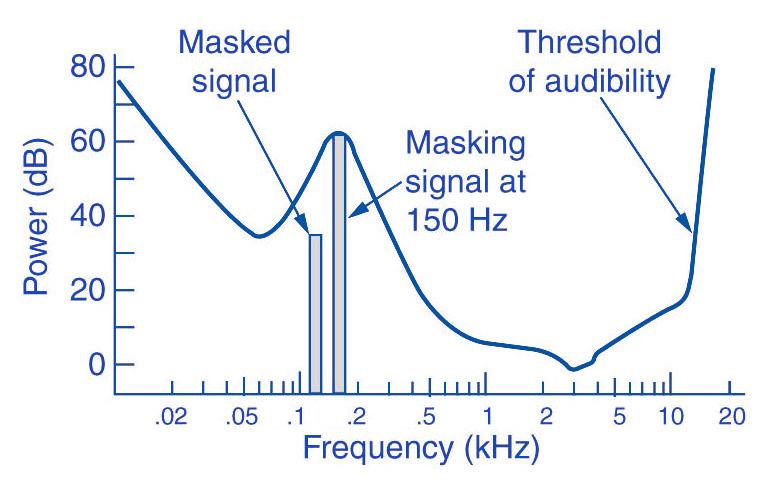
This principle is based on auditory masking, where louder sounds mask softer ones in similar frequencies. For example, a drumbeat can overpower a faint whisper in a recording. MP3 encoding uses this natural phenomenon to reduce file size by discarding sounds you wouldn’t hear anyway. It’s an elegant way of mimicking how our ears work.
How MP3 divides and processes frequency bands
MP3 encoding divides audio into 32 sub-bands using a filter bank, much like slicing a pizza into smaller pieces. Each slice— or sub-band—represents a portion of the audio spectrum. The encoder assigns bits to these slices based on their importance and complexity.
Critical bands, such as those carrying vocals or melody, receive more bits to preserve quality. Meanwhile, less significant bands, like subtle background noise, are given fewer bits. This division allows MP3s to shrink file sizes dramatically without losing the essence of the audio.
The importance of bit allocation per band
Bit allocation per band in MP3 encoding is like budgeting money. You spend more on essentials, like rent, and less on luxuries, like a fancy coffee. In MP3s, bits are currency, and they’re distributed across frequency bands based on priority.
When a band carries complex or prominent sounds, like a lead guitar riff, the encoder assigns more bits to capture its detail. Simpler or quieter bands get fewer bits, preserving overall quality while minimizing file size. This selective allocation ensures an efficient use of storage space.
Challenges with frequency band allocation
Frequency band allocation isn’t without its hurdles. One challenge is balancing compression and quality. Over-compression can make audio sound “tinny” or lose its depth. I’ve heard poorly encoded files where vocals sounded muffled, ruining the listening experience.
Another issue is compatibility. Not all playback devices process MP3s equally well. Older hardware might struggle with files that heavily compress certain frequency bands. This makes finding the right encoding balance vital for universal usability.
Advanced techniques to improve frequency band allocation
Advancements in MP3 encoding have introduced smarter ways to handle frequency bands. Dynamic bit allocation, for example, adjusts bit distribution in real-time based on audio complexity. It’s like turning up the AC in a car when driving through a hot desert—adaptive and efficient.
Another technique is joint stereo, which optimizes how stereo channels share data. Instead of encoding each channel separately, joint stereo focuses on shared information, saving bits without sacrificing quality. These innovations keep MP3s relevant even as audio technology evolves.
Frequency band allocation in modern MP3 encoding
Modern MP3 encoding leverages AI-driven algorithms to refine frequency band allocation. These algorithms analyze the audio content more accurately, predicting how listeners will perceive changes. I’ve noticed newer MP3s sounding much richer despite smaller file sizes, thanks to these advancements.
Additionally, encoders now focus more on preserving spatial cues. For example, they ensure that a listener can still distinguish instruments in a symphony, maintaining an immersive experience. This shift toward perceptual accuracy shows how far MP3 technology has come.
Latest words on frequency band allocation in MP3 encoding
Frequency band allocation in MP3 encoding is an intricate dance of science and art. By prioritizing the most critical sounds and optimizing bit distribution, MP3s achieve a balance between quality and file size. This process, rooted in psychoacoustics, has made MP3s a cornerstone of digital audio.
If you’re looking for a way to enhance your MP3 files, Mp4Gain offers tools to improve their sound quality. It’s an excellent choice for users who want more control over their audio files.
FAQ About frequency band allocation
What is frequency band allocation?
Frequency band allocation is the process of dividing an audio signal into distinct frequency ranges, optimizing how they’re encoded to preserve quality.
Why is frequency band allocation important in MP3 encoding?
It helps reduce file size by prioritizing important sounds and discarding inaudible ones, maintaining a balance between quality and compression.
How do psychoacoustics influence MP3 encoding?
Psychoacoustics determines how humans perceive sound, guiding MP3 encoding to focus on audible frequencies and mask others.
What are critical bands in MP3 encoding?
Critical bands are frequency ranges that our ears process similarly, helping encoders decide where to allocate bits most efficiently.
How does dynamic bit allocation work?
Dynamic bit allocation adjusts the number of bits assigned to frequency bands in real-time, depending on audio complexity.
What is joint stereo in MP3 encoding?
Joint stereo encodes shared audio data between channels, reducing file size while preserving stereo effects.
Can MP3 encoding handle spatial audio?
Modern MP3 encoders incorporate techniques to preserve spatial cues, ensuring an immersive listening experience.
How do modern MP3 encoders differ?
They use AI-driven algorithms for better frequency band allocation, improving quality without increasing file size.
What are the challenges of frequency band allocation?
Challenges include balancing compression and quality, ensuring compatibility with devices, and preserving auditory depth.
How does frequency band allocation improve MP3s?
It ensures the most important sounds are preserved, creating high-quality files that are compact and efficient.





Comments:
This was super helpful! I always wondered how MP3s manage to keep their quality while being so small.
Wow, learned so much. Could you go deeper into the role of AI in MP3 encoding? That part fascinated me!
I don’t know about anyone else, but my old MP3 files sound nothing like this description. Is there a way to fix them?
This makes it so much easier to understand. The comparison to packing a suitcase nailed it. Thanks a ton!
Great article. I still feel like some points about joint stereo could be clearer. Maybe add an example?
This article really explained things in a simple way. It’s exactly what I needed for my music project.