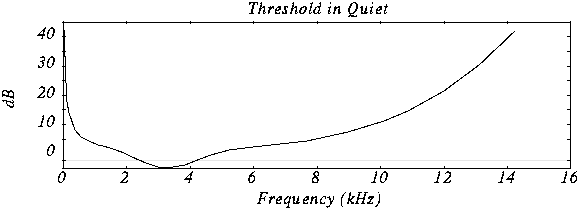
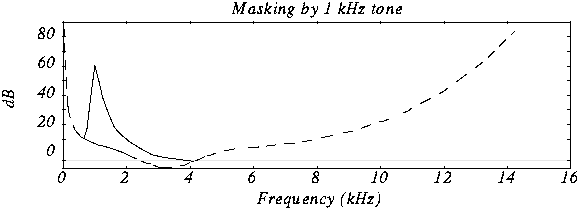
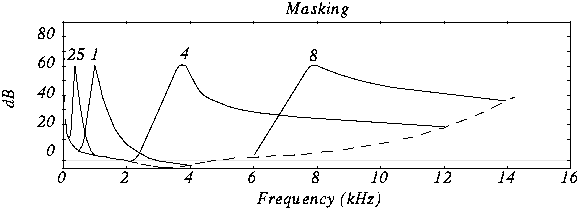
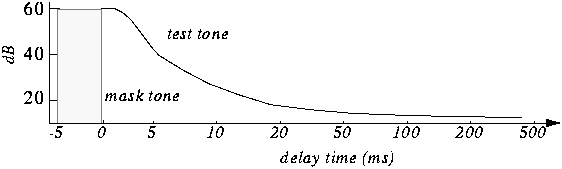
Mp3 (an audio encoding method) Part 3
To generate bit-compliant (Layer 1.Layer 2.Layer 3) MPEGAudio files, ISO MPEG Audio committee members developed reference simulation software in C called ISO 11172-5.

It can demonstrate the first real-time DSP-based hardware decoding of compressed audio on some non-real-time operating systems. Various other MPEG audio was developed in real time for digital broadcasting (DAB radio and DVB TV) for consumer receivers and set-top boxes.
Later on July 7, 1994, Fraunhofer-Gesellschaft released the first MP3 encoder called l3enc.
The Fraunhofer development team selected the .mp3 extension on July 14, 1995 (previously the extension was .bit). Using Winplay3 (released September 9, 1995), the first real-time software MP3 player, many people were able to encode and play MP3 files on their own personal computers. Since hard drives at the time were relatively small (such as 500MB), this technology was essential for storing entertainment music on computers.
MP2, MP3 and Internet
In October 1993, MP2 (MPEG-1 Audio Layer 2) files appeared on the Internet and were often played by Xing MPEG Audio Player and later MAPlay developed by Tobias Bading for Unix. MAPplay was first released on February 22, 1994 and ported to the Microsoft Windows platform.
The only MP2 encoder products at first were Xing Encoder and CDDA2WAV, a CD ripper that converts audio tracks from CDs to WAV format.
Often considered the father of the online music revolution, the Internet Underground Music Archive (IUMA) was the first hi-fi music site on the Internet, with thousands of licensed MP2 recordings before MP3 and the web became popular. .
From the first half of 1995 to the end of the 1990s, MP3 began to flourish on the Internet. MP3’s popularity is largely due to the success of companies and software packages such as Winamp released by Nullsoft in 1997 and Napster released by Napster in 1999, and they are mutually reinforcing. These programs make it easy for normal users to play, create, share and collect MP3 files.
The debate about sharing MP3 files between peers has spread rapidly in recent years, mainly because compression makes file sharing possible, uncompressed files are too large to share. Since MP3 files are widely spread over the Internet, Napster has been sued by some of the major record labels to protect their copyright (see Copyright).
Commercial online music distribution services, such as the iTunes Music Store, often choose other proprietary or DRM-enabled music file formats to control and limit the use of digital music. Formats that support DRM are used to protect copyrighted material from copyright infringement, but most protection mechanisms can be broken in some way. Computer experts can use these methods to generate unlocked files that can be freely copied. One notable exception is Microsoft’s Windows Media Audio 10 format, which has yet to be cracked. If a compressed audio file is desired, the recorded audio stream must be compressed and the sound quality will be degraded.
streaming audio quality
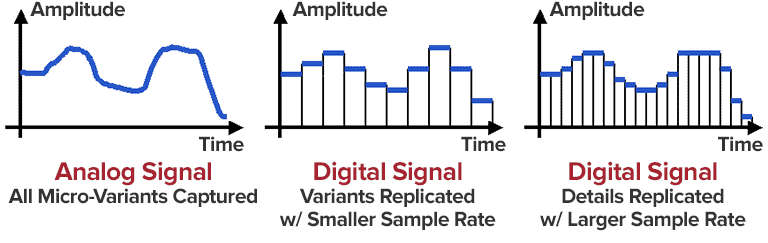
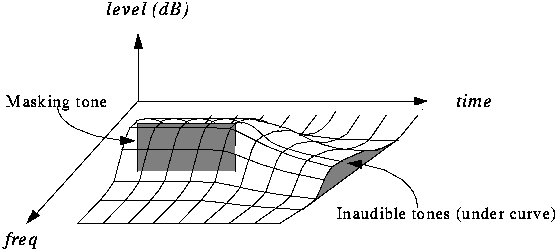
Because MP3 is a lossy compression format, it offers a variety of options for different “bit rates,” that is, the number of encoded data bits needed to represent the audio per second. Typical speeds are between 128 kbps and 320 kbps (kbit/s). In contrast, the uncompressed audio bitrate on a CD is 1411.2 kbps (16 bits/sample × 44100 samples/sec × 2 channels).
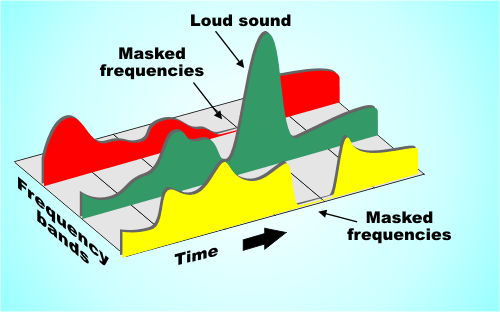
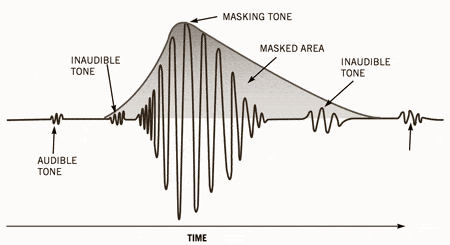
MP3 files encoded with lower bit rates generally play at a lower quality. If you use too low a bitrate, “compression artifact” (sounds not present in the original recording) will appear during playback. A good example of compression noise is the sound of compressed cheering; due to its randomness and sharp changes, encoder errors are more pronounced and sound like echoes.