
MP3 COMPRESSION
To achieve such a dramatic reduction in the number of bits required to transmit an MP audio signal, use different techniques. These techniques include those based on perceptual coding and others such as byte reservation, stereo assembly or Huffman codes. Percentage coding consists of removing all the information that goes into the audio signal that the human ear is not capable of detecting. We will now describe them:
PERCEPTUAL CODING
Minimum hearing threshold The ear’s minimum hearing threshold is the power below which a tone at a given frequency is not capable of being detected by the ear. This threshold is non-linear. As we see in the figure, which represents the Fletcher and Mundson law, the frequencies in which we hear best are those between 2 and 5 Khz. Therefore frequencies outside that band are not totally essential since they will hardly be perceived. Therefore it is possible to remove the content of the audio signal outside these frequencies.
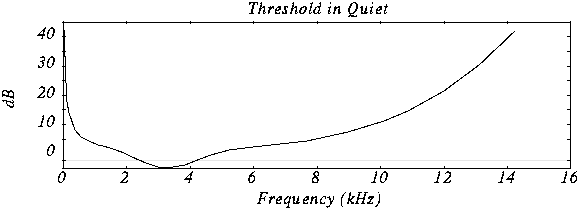
As we can see in the drawing, the range in which a lower power is needed for the tone to be heard is between 2 and 4 Khz.
The masking effect This effect consists in that, when an audio signal has a tone at a given frequency, it produces a masking effect at the frequencies close to it, so that if at these nearby frequencies the signal does not exceed a certain power threshold cannot be heard and therefore it is not necessary to encode them. The form that this power threshold will take according to the position of the tone or the masking tones is what is called the psychoacoustic model, which as the name itself indicates is a perception model that tries to emulate the perception of the human ear.
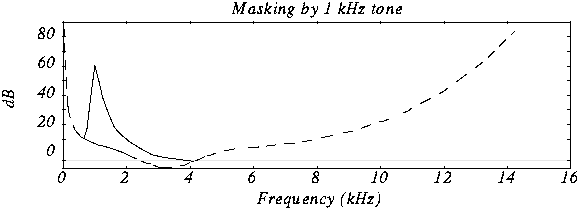
In this graph we can see how if we put a tone at 1 Khz of 60 dB (masking tone) and then we put another tone at, for example 1.1 Khz and we vary the frequency of this, it is not possible to detect the presence of this second tone until its power exceeds the threshold presented in the figure.
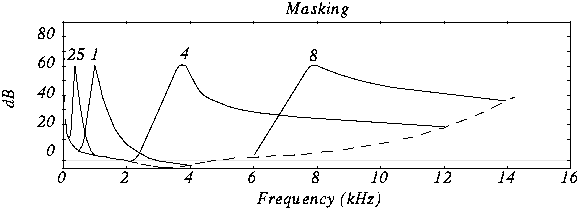
In this case we see various masking tones and the resulting new hearing thresholds. In MP3, what is done is to divide the spectrum to be transmitted (that is, between 2 and 5 Khz) into frequency subbands, so that the power of the subband is evaluated and the masking threshold is created in the nearby subbands. Nearby subbands that exceed that power threshold are coded and those that do not exceed it are not coded.
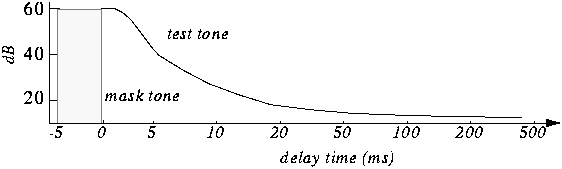
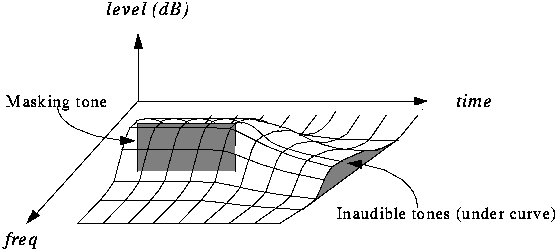
Furthermore, the masking is not only in appearance but also in time as we can see in the figure.
The byte reserve: Often, some passages of a musical piece cannot be encoded at the same rate without altering the quality of the music. MP · then uses a small byte reservation that acts as a buffer using the capacity of passages that can be encoded at a lower rate in the given stream.
The stereo assembly In the case of a stereo signal, the MP3 format can use a few more tools to further compress the data.
Intensity stereo (IS) The human ear is not able to locate with complete certainty the spatial origin of sounds for very high or very low frequencies. This technique takes advantage of this, recording some frequencies as a monophonic signal, so that a minimum of spatial content is subtracted from the sound.
Mid / Side (M / S) Stereo When the left and right channels are similar then a middle channel (L + R) and a side channel (LR) are created, which are encoded instead of encoding the left channel on one side and the right for another. In this way it is possible to reduce the transmitted data using fewer bits for the lateral channel. Then during playback the MP3 decoder will reconstruct the left and right channels.
Huffman Coding: This coding technique is used at the end of the whole process. It works by creating variable-length codes, so that the symbols that appear in the bitstream most likely have shorter codes. The translation between symbols and codes is done using a table. Each code has a unique prefix so that the codes can be decoded correctly despite their variable length. This type of coding allows on average to reduce by 20% the amount of data to be transmitted. It is an ideal complement to perceptual coding since, during great polyphonies, perceptual coding is very efficient since many sounds are masked, but nevertheless little information is identical and Huffman’s algorithm becomes inefficient. During pure sounds there are few masking effects, but Huffman encoding is very efficient since digitized sound contains many repeating bytes.

