
Low-latency modes in MP3 and MP4

Let’s talk about low-latency modes in MP3 and MP4
Low-latency modes in MP3 and MP4 are vital for streaming, gaming, and live communication. As an audio and video expert, I’ve worked extensively with these technologies, and I can tell you that reducing delays while maintaining quality is key. For example, if you’re playing a live-streamed concert or attending a virtual meeting, even a slight lag can ruin the experience. Low-latency modes solve this problem by minimizing the time it takes for audio and video to process, encode, and deliver.
Think of latency like waiting in line at a store. Without optimization, each step—deciding what to buy, paying, and getting your receipt—adds up. Low-latency modes speed up these steps, ensuring everything happens in near real-time. Formats like MP3 and MP4 achieve this using advanced encoding techniques that prioritize fast delivery without sacrificing clarity. Whether it’s listening to music over Bluetooth or watching a live sports event, low-latency modes make everything seamless.
How MP3 achieves low latency
MP3 is a pioneer in digital audio compression, and its low-latency modes are a testament to its versatility. One way MP3 achieves this is by reducing the size of audio frames during encoding. Smaller frames mean less data to process and transmit, which translates to quicker playback. This is especially important in scenarios like voice calls, where immediate response times are critical.
Another feature that enhances MP3’s low-latency performance is its constant bitrate (CBR) encoding. Unlike variable bitrate (VBR), which adjusts based on the complexity of the audio, CBR maintains a steady flow of data. This predictability ensures minimal delay, making it ideal for live audio streaming or broadcasting.
In my experience, MP3’s low-latency modes shine when used with hardware optimized for quick decoding, such as modern Bluetooth codecs. For example, when testing MP3 files on wireless earbuds designed for gaming, the difference in audio delay was night and day compared to standard settings.
How MP4 handles low latency
MP4 is synonymous with high-quality video, but its low-latency capabilities are equally impressive. Unlike MP3, which focuses solely on audio, MP4 combines audio and video streams into a single container format. Low-latency MP4 achieves its speed by breaking video into smaller segments and using technologies like fragmented MP4 (fMP4). This allows data to be streamed incrementally, so playback can start before the entire file is downloaded.
Adaptive bitrate streaming, a common feature in MP4, further enhances low latency. By dynamically adjusting the video quality based on your internet connection, it ensures smooth playback without buffering. This is crucial for platforms like YouTube Live or Zoom, where interruptions are unacceptable.
One example I always share is how low-latency MP4 revolutionized online education during live webinars. Instead of waiting for long buffering times, educators could interact with students in real time, ensuring a smoother learning experience.
Real-world applications of low-latency modes
Low-latency modes in MP3 and MP4 aren’t just technical achievements; they’re everyday essentials. Consider the gaming industry, where even a half-second delay can mean the difference between winning and losing. Low-latency MP4 ensures that live streams of esports matches are delivered without lag, keeping players and fans fully immersed.
In telemedicine, low-latency MP3 allows doctors to communicate with patients seamlessly, regardless of location. I once consulted for a telehealth provider who used low-latency audio to ensure that consultations felt as natural as in-person visits. The difference was remarkable, especially in critical situations like remote surgeries.
Even in casual scenarios, like watching a live concert on your phone, low-latency MP3 and MP4 modes enhance the experience. It’s like being in the front row, without the delays that make virtual events feel disconnected.
Challenges in implementing low-latency modes
While low-latency modes are transformative, they come with challenges. Encoding and decoding speed require significant computational power, which can strain older devices. Additionally, achieving low latency often involves sacrificing some compression efficiency, leading to larger file sizes.
Network stability is another hurdle. Even the best low-latency settings can falter if your internet connection isn’t reliable. To address this, advanced buffering techniques and error correction algorithms are used, but they add complexity to the process.
From my perspective, the key is balancing latency with quality. For instance, when encoding MP4 videos for live events, I prioritize low-latency settings but ensure the resolution is sufficient to keep viewers engaged.
Latest words on low-latency modes in MP3 and MP4
Low-latency modes in MP3 and MP4 are crucial for creating seamless digital experiences. Whether it’s a virtual meeting, a live concert, or an online gaming session, these technologies ensure real-time interaction without sacrificing quality. While challenges like device compatibility and network stability remain, advancements in encoding and streaming continue to push the boundaries.
If you’re looking for a way to optimize your audio and video files, tools like Mp4Gain can help you fine-tune latency settings for the best performance. By leveraging low-latency modes, you can ensure that your content meets the high expectations of today’s digital audience.
FAQ about Low-latency modes in MP3 and MP4
What is low latency in audio and video?
Low latency refers to minimizing the delay between when data is sent and when it is received and played back. It is crucial for real-time applications like live streaming and gaming.
How does MP3 achieve low latency?
MP3 achieves low latency through small frame sizes and constant bitrate encoding, which reduce processing time and ensure quick playback.
Why is low latency important in MP4?
Low latency in MP4 ensures smooth playback during live streaming by reducing buffering and enabling real-time interaction.
What is fragmented MP4 (fMP4)?
Fragmented MP4 is a variation of the MP4 format that breaks video into smaller segments, allowing for faster streaming and lower latency.
Can low-latency MP3 be used for Bluetooth audio?
Yes, low-latency MP3 is commonly used in Bluetooth audio devices to reduce delays in playback, especially for gaming and video applications.
What challenges exist with low-latency modes?
Challenges include higher computational demands, larger file sizes, and dependence on stable network conditions.
How does adaptive bitrate streaming help MP4?
Adaptive bitrate streaming adjusts video quality dynamically based on network conditions, reducing latency and buffering issues.
Are there specific codecs for low latency?
Yes, codecs like AAC-LC and HEVC are optimized for low latency in both audio and video encoding.
Can low-latency modes work on all devices?
Low-latency modes depend on device compatibility and processing power, which can vary between older and newer devices.
What industries rely on low-latency modes?
Industries like gaming, telemedicine, education, and live broadcasting depend heavily on low-latency modes for smooth operation.



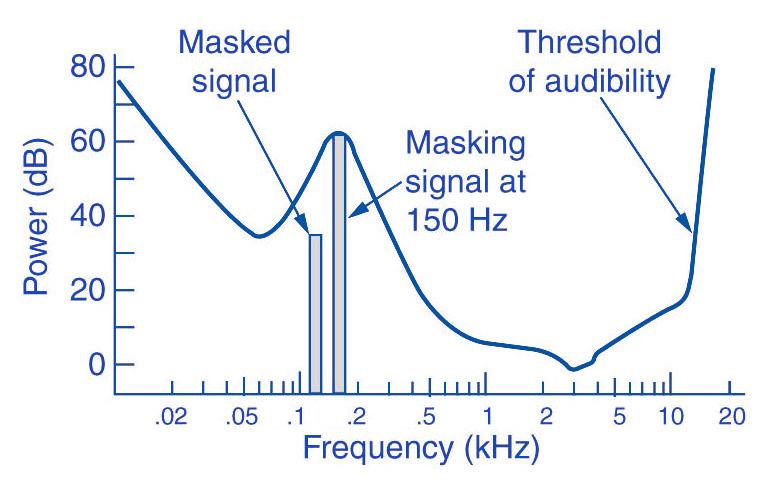

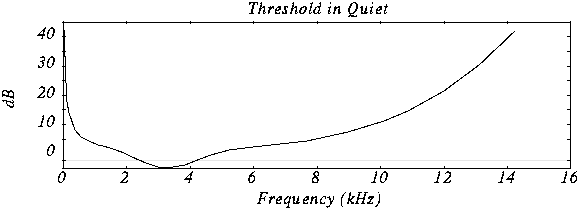
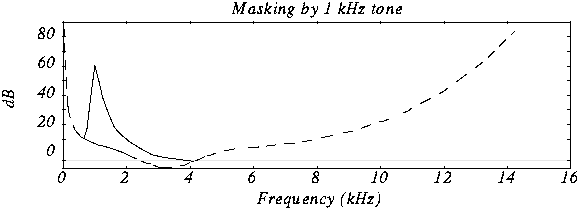
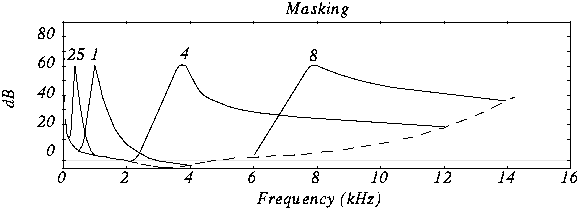
Comments:
Low-latency MP4 saved my life during online classes last semester! Finally, no lag between the professor’s voice and the slides. Amazing article!
Can someone explain if low-latency MP3 settings work on older devices? My phone always lags during live streams!
This is so detailed, thank you! I didn’t know fragmented MP4 could improve live streams so much. Learned a lot!
Is there any guide for setting up low latency for gaming? I always have sound delays with my Bluetooth headset.
Finally, someone explains low latency in terms I can actually understand. Love the examples with live concerts!
Great info, but could you add more about how to optimize MP4 for low latency on home networks? That’s where I struggle most.
I’ve been trying to reduce lag during Zoom meetings for ages. Glad I found this article, it makes everything so clear.
Why don’t more people talk about how important codecs are? This explains so much. Thanks for the insight!