ENCODING PRINCIPLES OF THE MP3 FORMAT.
Mp3, or fully MPEG-1, 2 and 2.5 Layer 3, is one of the most popular and widespread standards for storing audio data.

In this article, we will not delve into the history of creation and further development, but will consider the basic principles of the standard and examples of its implementation.
The mp3 standard does not establish a specific compression algorithm to “encode” the source data, but rather describes the essence of the possible methods.
The quality of the result obtained depends on the modification of the algorithm used, embedded in any encoding program of the “codec”, and on the quality of the original audio data.
There are 3 most common modifications of the mp3 format, which differ in the compression ratio parameters of the original audio data.
Name
Modification of the rule
Data rate per second (bit rate) Possible sample rates
MPEG-1 layer 3
32 – 320 kbps 32000 Hz
44100 Hz
48000 Hz
MPEG-2 Layer 3 16 – 160 kbps 16000 Hz
22050 Hz
24000 Hz
MPEG-2.5 Layer 3 8 – up to 160 kbps 8000 Hz
11025 Hz
Processing begins with dividing the original audio signal into equal time intervals: equal frames, for example 0.05 or 0.26 seconds, after which each frame is analyzed and compressed according to general or individual parameters based on the data of the previous and next frames.
Most of the compression algorithms used are based on the perceptual characteristics of the human ear. Let’s consider the main options, which, as a rule, are applied in a complex way.
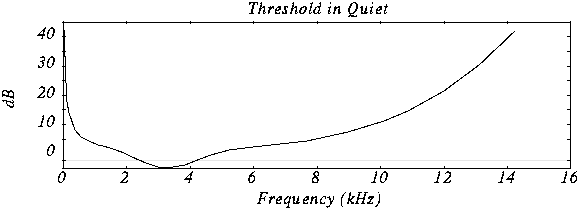
It is worth starting with the fact that, by ear, the average person is capable of perceiving a frequency range of approximately 10 Hz to 20,000 Hz. With growth, changes occur in the hearing aid and, for most, the sensitivity the higher frequency range decreases, as a result of which, in some mp3 modifications, during compression, all frequencies above 16000 hertz are cut off, which can significantly reduce the amount of information.
Audio recordings can be encoded in stereo (a surround sound effect that uses separate channels for the left and right speakers) or mono (the opposite of stereo). In mp3 format, different tracks are not recorded for each of your speakers, but information about the differences between the left and right channels.
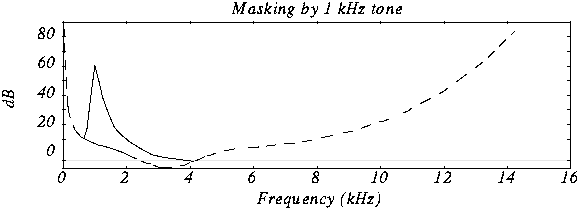
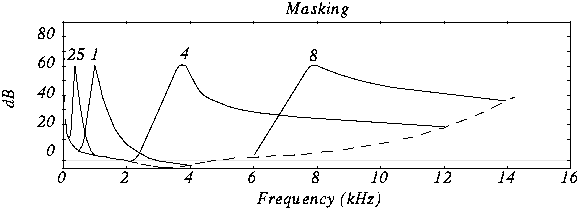
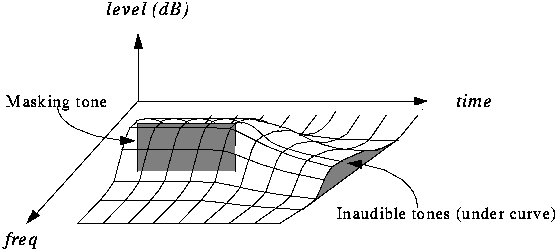
In acoustics, there is a concept like “harmonics”, these are the frequencies of the “sounds” that sound together with the main and most prominent tone. For example, when hitting a drum, the loudest sound will be the tone and the minor, weaker, will be the harmonics.
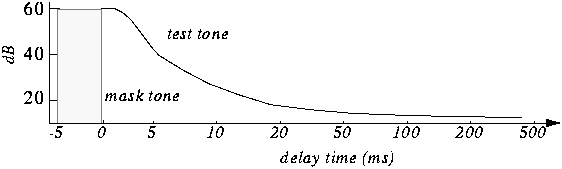
After such a loud sound, the so-called “period of deafness” occurs, during a period of duration in which a person’s hearing practically does not respond to changes.
If in the intervals of the “deafness period”, remove all frequencies, then the errors of perception, will practically not allow to notice their absence, because of this, during compression, the weakest harmonics are cut off, located close to the most sounds. strong: tones.
A method is used to replace the near peak values of the signal “peaks” (in terms of volume) with an average value.
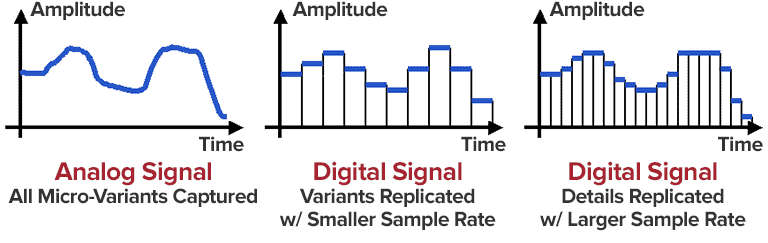
There is a concept as bit rate: this is a value that characterizes the number of transmitted bits of information “units” during a period of time, usually one second.
The higher the bit rate, the better the audio detail will be, as long as the original, uncompressed audio data is of high quality.
As you can guess, digital formats consist of certain code sequences, in other words of sequences 0 and 1.
To save space, frequent joins within a file are assigned unique identifiers that replace long sequences.
Thanks to such complex influences, it is possible to compress the original audio signal into one of the popular formats with loss of quality – the mp3 format.
Various experiments have been carried out many times in order to reveal how significant the differences are before and after compression in mp3. As tests have shown, differences, some similar moments were not always possible, quickly and to distinguish, even when reproduced on equipment with higher fidelity.
For those who have never had the opportunity to directly compare the original and compressed audio recording, in most cases it will take some time or even find obvious differences.