Audio Normalization Techniques: Peak vs. Loudness
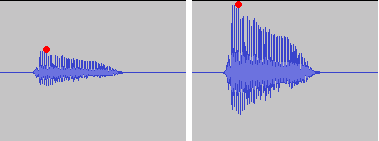

As an audio optimization expert, I’m often asked about the best techniques for normalizing audio levels. In this article, I will explore two popular approaches: peak normalization and loudness normalization. These techniques, peak vs. loudness normalization, have their own unique advantages and considerations. Let’s dive in and uncover the secrets of achieving balanced and consistent audio!
Peak Normalization: Unleashing the Power of Dynamics
When it comes to peak normalization, it’s all about preserving the dynamics of your audio. Imagine a breathtaking symphony where the crescendos and diminuendos transport you to a different realm. With peak normalization, you ensure that the highest peaks of your audio reach their full potential without clipping or distortion. It’s like giving your audio the freedom to express itself with intensity and impact.
Loudness Normalization: The Harmony of Consistency
Now, let’s turn our attention to the world of loudness normalization. Have you ever experienced the frustration of constantly adjusting the volume while switching between songs or TV shows? Loudness normalization comes to the rescue! By analyzing the perceived loudness of your audio, it ensures a consistent listening experience across different tracks. Say goodbye to sudden volume jumps and immerse yourself in a harmonious soundscape.
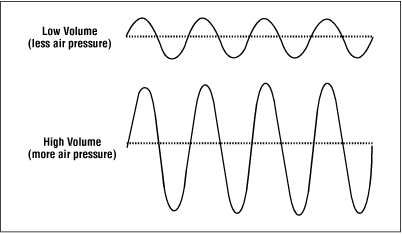
Dynamic Range: The Dance of Soft and Loud
In the realm of audio normalization, we encounter the concept of dynamic range. Dynamic range represents the difference between the softest and loudest parts of an audio signal. Peak normalization respects the natural dynamic range, allowing the delicate whispers and thunderous roars to coexist in perfect balance. On the other hand, loudness normalization aims to reduce the dynamic range, providing a more even playing field for all elements of your audio.
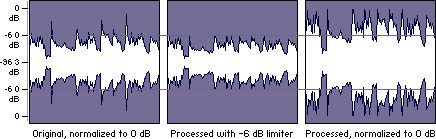
Audio Clipping: Taming the Wild Peaks
Audio clipping is a notorious villain that can ruin your audio experience. Picture this: a sudden burst of sound that distorts and crackles, disrupting your enjoyment. Peak normalization acts as the hero in this story, taming those wild peaks and ensuring that your audio stays within safe limits. With peak normalization, your audio remains clean and free from the dreaded clipping monster.
LUFS: The Measure of Perceived Loudness
In the realm of loudness normalization, we encounter the term LUFS, which stands for Loudness Units Full Scale. LUFS provides a standardized measure of the perceived loudness of your audio. Loudness normalization algorithms analyze the integrated LUFS value and adjust the overall volume to match a specific target level. It’s like having a universal translator that ensures consistent loudness across different tracks and platforms.
Listening Environment: From Living Rooms to Concert Halls
Let’s talk about the listening environment and its impact on audio normalization. Every space has its unique characteristics, from the cozy intimacy of a living room to the grandeur of a concert hall. Loudness normalization takes into account these variations, delivering a consistent listening experience regardless of the environment. So whether you’re enjoying your favorite tunes at home or attending a live performance, the magic of normalization will make every moment memorable.
Personal Preference: Customizing Your Audio Journey
We all have our individual tastes and preferences when it comes to audio. Some crave the raw power of peak normalization, while others seek the comfort of consistent loudness through loudness normalization. The beauty of audio normalization techniques is that they allow you to customize your audio journey according to your personal taste. It’s like having a tailor-made suit that perfectly fits your unique style.
Metadata and Replay Gain: Enhancing the User Experience
Metadata and Replay Gain are powerful allies in the realm of audio normalization. Metadata provides valuable information about your audio, guiding normalization algorithms to make the right adjustments. Replay Gain takes it a step further by applying metadata tags to your audio files, ensuring consistent playback volume across different tracks. Together, they create a seamless and enhanced user experience, elevating your audio enjoyment to new heights.
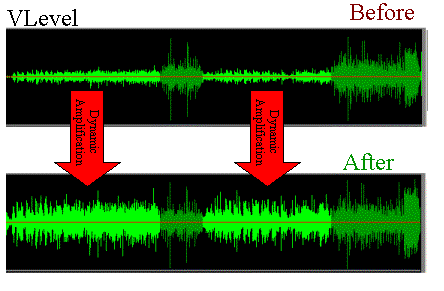
Compression: Controlling the Sonic Landscape
Dynamic audio content, such as movies or live performances, often presents challenges for normalization. This is where compression enters the scene. Compression techniques allow you to shape the sonic landscape, reducing the dynamic range while maintaining audio quality. It’s like having a skilled conductor who ensures that every instrument is heard clearly, regardless of its volume.
Audio Editing and Mastering: Polishing the Gems
Lastly, let’s not forget the crucial role of audio editing and mastering in the pursuit of sonic perfection. Audio professionals meticulously fine-tune various parameters during the editing and mastering process. Audio normalization techniques become valuable tools in their arsenal, ensuring that the final product shines with balanced and consistent audio. It’s like adding the final touch of brilliance to your audio gems.
In conclusion, the choice between peak normalization and loudness normalization depends on your desired audio outcome. Whether you embrace the dynamic range or seek consistent loudness, these techniques empower you to create an audio experience that resonates with your vision. So go forth, unleash the power of normalization, and let your audio journey be a harmonious symphony of sound!