Normalization of an audio file.
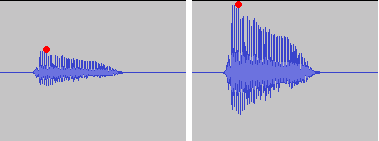
Normalization is used to increase or decrease the level of the song as a whole, so that its maximum volume peaks assume the indicated level.

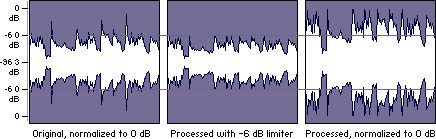
For example, if the maximum intensity points of the song are -3 dB (therefore well below 0, which should represent the maximum before distortion), normalizing to 0 dB means increasing the level of the entire song so that these peaks reach 0 dB.
This is the typical normalization of the peaks.
There is also RMS normalization (which takes into account not the peaks but the actual average level of the song).

AUDIO CDs, which have good dynamic possibilities (various intensity tones, from pianissimo to fortissimo), are generally recorded so that the maximum volume points are at 0 dB.
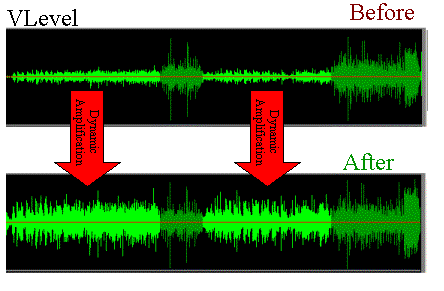
Normalizing your WAV recordings can be helpful in adjusting them to the average level of a CD in case they are too low (because you had been careful in level during recording) but one important thing to note:
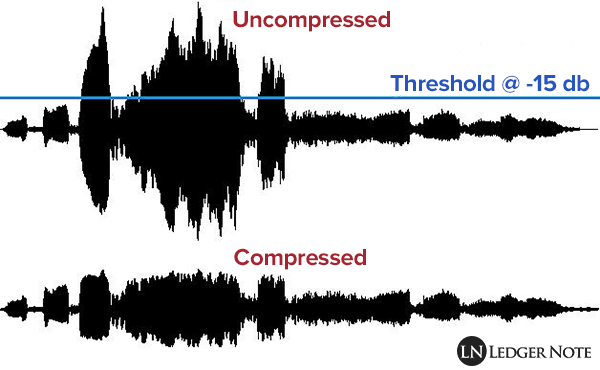
Normalization of this type alters the original dynamics, that is, the reciprocal relationships between weak and strong sounds.
Although all levels are raised by the same amount, the relationship between 2 levels changes (small mathematical example:
2/5 = 0.4 ma (2 + 1) / (5 + 1) = 0.5 …
The result is that the weaker sounds, after abrupt normalization, sound much louder and those that were already playing only sound a little louder … altering the dynamic relationships that had been envisioned by those who originally recorded the music and making the sound output to lose depth.
Some types of music, generally already deficient dynamics (rock, metal, etc.) since the excursions between the minimum and maximum volume are almost never very consistent, are more “normalizable” without problems, while the genres in which there may be Large Dynamic excursions (classical music or music with passages from pianissimi to fortissimi) are more problematic.
In addition, it is necessary to take into account that if you normalize a large wav file that contains many songs (not yet divided) there can still be, even in genres with little dynamics, substantial differences, in this case between one song and another and not between different points of the same song.
So a light normalization can do and is actually used (to raise the level of the part), but it would be better to make sure you don’t need it (recording from the beginning with a good level) or at least not have too much. remember, however, that the dynamics are somewhat flattened.
Normalize with Mp4Gain
This software is capable (it is the only one that can do this) of normalizing the main audio and video formats and its standardization algorithm is by far the most efficient and the one that produces the best results.
For this reason it is used by musicians, radio broadcasters, universities, television stations, producers, etc.