Mp3, description of audio compression technique
Digitization
Sound is a continuous wave that propagates through air or other media, formed by pressure differences, so that it can be detected by measuring the pressure level at a point. Sound waves have the proper and studyable characteristics of waves in general, such as reflection, refraction and diffraction.

To the Being a continuous wave, a digitization process is required to represent it as a series of numbers. Currently, most of the operations performed on sound signals are digital, since both storage and
Processing and transmitting the signal in digital form offers very significant advantages over analog methods. Digital technology is more advanced and offers greater possibilities, less sensitivity to transmission noise and the ability to include error protection codes, as well as encryption. With the appropriate decoding mechanisms, moreover, they can be processed simultaneously signals of different types transmitted by the same channel. The main disadvantage of the digital signal is that it requires a much greater bandwidth than that of the analog signal, hence an exhaustive study is carried out regarding data compression, some of whose techniques will be the center of our study.
Digitalization of the audio
The digitization process consists of two phases: sampling and quantization. At sampling divides the time axis into segments
discrete: the sampling frequency will be the inverse
the time between a measurement and the
following. At this time the
quantization, which, in its simplest form,
it simply consists of measuring the value of the signal
in breadth and save it.
Nyquist’s theorem
Nyquist’s theorem ensures that the frequency required to sample a signal that has its highest components at a given frequency f is at least 2f. Therefore, being the upper range of human hearing around 20 Khz, the frequency that guarantees adequate sampling for any audible sound will be around 40 Khz.
Specifically, to obtain high quality sound, frequencies of 44’1 Khz are used,
in the case of CD, for example, and up to 48 Khz, in the case of DAT. Other typical values are submultiples of the first, 22 and 11 Khz.
Depending on the nature of the application, of course, the appropriate frequencies can be much lower, such that the voice process is usually performed at a frequency between 6 and
20 Khz. or even less. Regarding quantization, it is evident that the more bits used for the division of the amplitude axis, the “finer” the partition will be and therefore the less error when attributing a specific amplitude to the sound at each moment.
For example, 8 bits offer 256 levels of quantization and 16,65536. The dynamic range of human hearing is about 100 dB. The axis division can be carried out at equal intervals or according to a specific density function, seeking more resolution in certain sections if the signal in question has more components in
certain zone of intensity, as we will see in the coding techniques.
The complete process is usually called PCM (Pulse Code Modulation) and we will refer to it hereinafter. It has been described in a very simplistic way, mainly because it is widely treated and is well known, being
another the field of study of this work. However, we will go into detail at any time that is necessary for the development of the exhibition.
Coding and Compression.
Before describing coding and compression systems, we must pause in a brief analysis of human auditory perception, to understand why a significant amount of the information provided by PCM can be discarded.
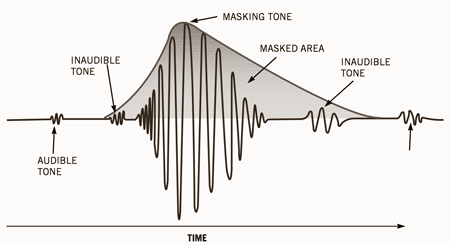
The heart of the matter, as far as we are concerned, is based on a phenomenon known as masking.
The human ear perceives a frequency range between 20 Hz. And 20 Khz.
Firstly, the sensitivity is greater in the area around 2-4 Khz., So that the sound is more difficult to hear the closer to the ends of the scale.
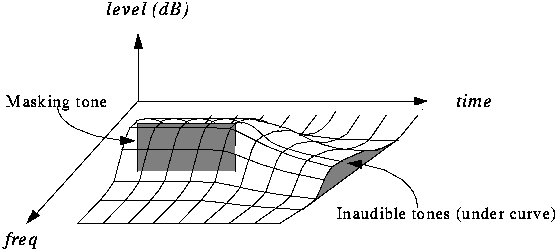
Second is masking, the properties of which are used extensively by the most interesting algorithms: when the component at a certain frequency of a signal has high energy, the ear cannot perceive lower energy components at close frequencies, both lower and higher.
At a certain distance from the masking frequency, the effect is reduced so much that it is negligible; the range of frequencies in which the phenomenon occurs is called the critical band.
The components that belong to the same critical band influence each other and do not affect nor are affected by those that appear outside it. The width of the critical band is different according to the
frequency in which we are located and is given by certain data that shows that it is greater with frequency.
It should be noted that these data are obtained by psychoacoustic experiments, which are carried out with experts trained in
sound perception, giving rise to psychoacoustic models with their impressions.
This we have described is the so-called simultaneous or frequency masking.
There is also the so-called asynchronous or time masking, as well as other phenomena of hearing that are not relevant in this point. For now, let’s focus on the idea that certain signal frequency components support higher noise than we would generally consider to be tolerable, and therefore require fewer bits to be encoded if the encoder is endowed.
of the right algorithms to solve masks.
Digitizing the signal using PCM is the simplest form of signal encoding, and is used by both CDs and DAT systems. Like still digitizing, it adds noise to the signal, generally undesirable. As we have seen, the fewer bits used in sampling and quantization, the greater the error in
accept discrete values for the continuous signal, that is, the higher the noise.
To avoid that the noise reaches an excessive level, it is necessary to use a large number of bits, so that at 44.1 Khz. and using 16 bits to quantize the signal, one of the two channels on a CD produces more than 700 kilobits per second (kbps). As we will see,
Much of this information is unnecessary and takes up bandwidth that could be freed, at the cost of increasing the complexity of the decoder system and incurring some loss of quality.
The compromise between bandwidth, complexity and quality
it is the one that produces the different market standards and will form the essential part of our study.