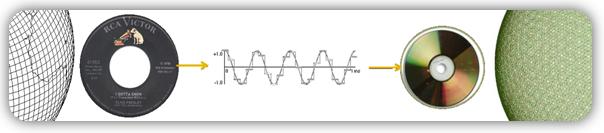
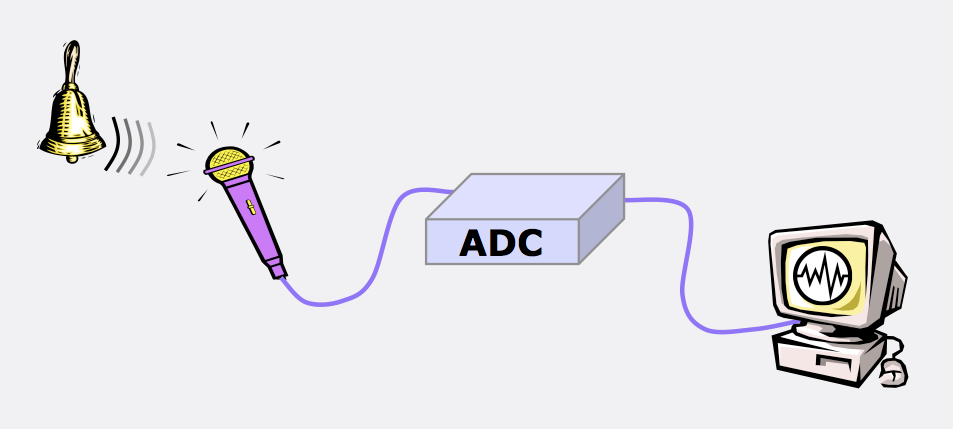
What is digital audio?

Digital sound is nothing more than a combination of numbers.
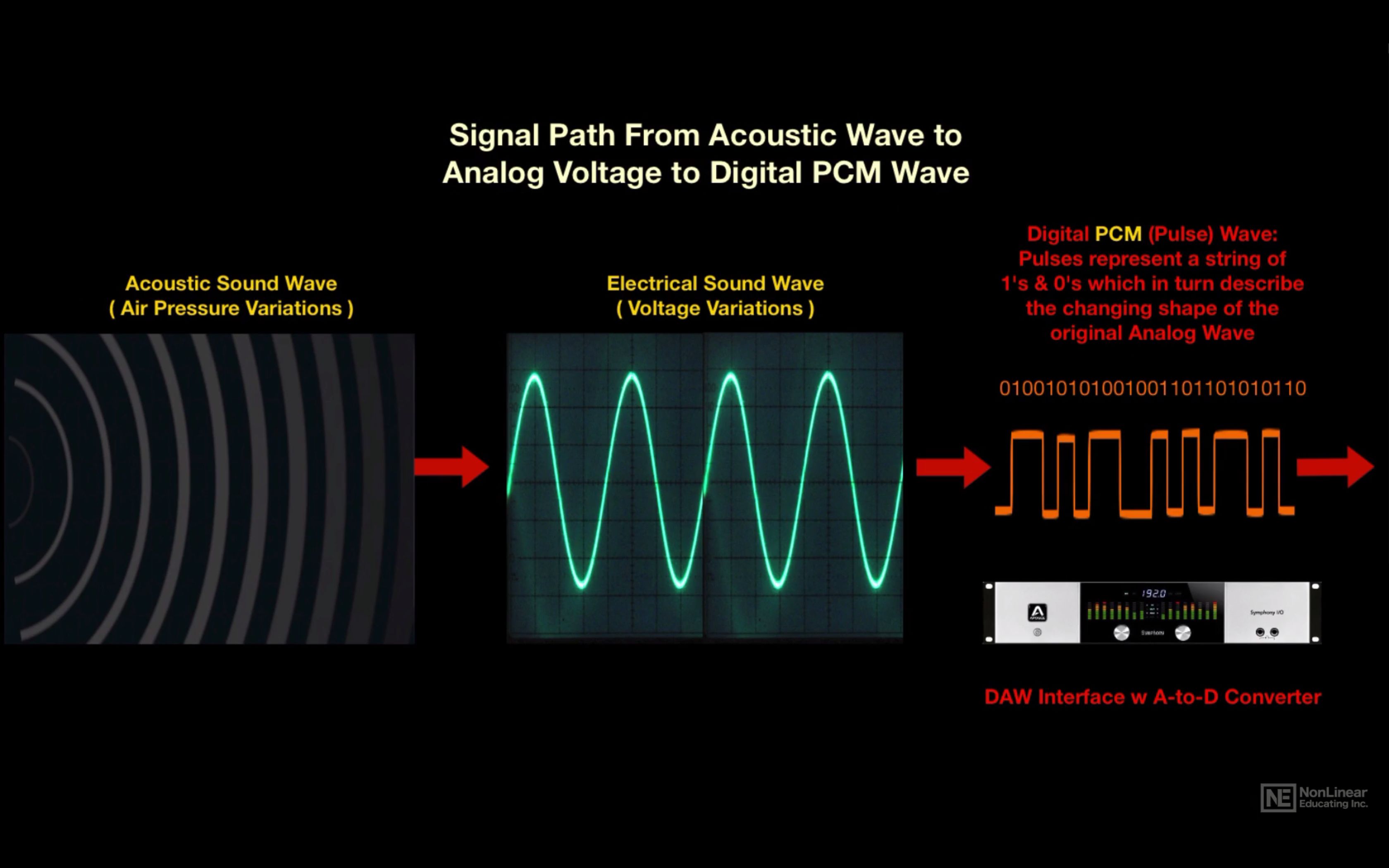
With a certain algorithm, sound, such as air pressure, is converted into data streams and encoded for further processing and playback. Depending on the algorithm used, the music file has one format or another, one or another extension.
Remember that along with digital sound, there is analog sound, which is represented by a continuous electrical signal that reflects the change in the sound wave. The analog to digital sound conversion is a setting of the numerical value of the amplitude at a given time with a given density of values. Consequently, the more values that are recorded, the more reliable and accurate the image of the digitized sound fragment is recreated. With such digitization, very voluminous data matrices emerge that, depending on the format used, differ in the sound quality / volume ratio of the final file.
Perhaps the main advantage of digital audio over analog is the ability to store and copy data indefinitely without losing the original quality (whereas when copying from one analog medium to another, a decrease in recording quality is quite noticeable).
The most widespread and popular digital audio format today is MP3 (MPEG Layer 3). It was developed, after a series of intermediate formats and investigations, started in 1987, by the Fraunhofer Institute in Germany.
The developers of the format were faced with the task of simplifying and reducing the cost of shipping long musical fragments. As you know, one minute of a stereo signal from a CD (16 bit, 44.1 kHz sample rate) takes up about ten megabytes of memory. At the same time, unlike text or graphic files, the audio signal cannot be compressed without loss of quality. Thus, modem transmission of an uncompressed composition from an audio CD lasting 3 minutes at a data transfer rate of, say, 24 kbps will take several hours. Scientists at the Fraunhofer Institute managed to achieve multiple file size compression: on average, one minute of a compressed audio signal in MP3 format takes about 1 megabyte. The principle of compression is based on the removal of “unnecessary” sounds from the music file, to which the human ear is immune, or which duplicate each other.
The main factor that determines the relationship between file size and sound quality within a given format is the bit rate. Bit rate is an indicator of how much information a second of sound encodes. The higher it is, the less distortion and the closer the encoded composition is to the original. The most common on the Internet are compositions with 128 and 192 Kbps bitrates. The maximum bitrate supported by programs and devices that work with MP3 is 320 Kbps. In practice, only an expert or a professional who works with sound can notice the differences between an MP3 file with a 320 bit rate.
To optimize the size of MP3 music files while maintaining decent quality, a variable bit rate (abbreviation VBR – variable bit rate) is used. In this case, the encoding program divides the file into fragments of different spectral saturation and encodes them with a suitable bit rate. Most modern MP3 players support variable bit rate playback. A significant advantage of MP3 files is that they can contain the name of the artist, the name of the track and the album, the year of its release, etc. The set of this data is called ID3 tags. Most modern gamers can read and display them on the screen.
In 2001, Swedish Coding Technologies and Thomson Multimedia developed the MP3 Pro codec. It is MP3-based and as a result is fully MP3 backward compatible and only partially forward compatible. It uses SBR (Spectral Band Replication) technology, so the codec provides good quality at low bit rates. However, the encoding quality at medium to high bit rates is inferior to that of most other codecs. For this reason, this format is mainly used for broadcasts on the Internet and demonstrations of fragments of new musical compositions.
Another type of MP3 was the development of MP3 Surround, recently introduced by the creators of MP3: the Fraunhofer Institute. This format repeats all the characteristics of multi-channel sound, while still being compatible with standard stereo MP3: information describing the spatial characteristics of the sound is recorded on an additional track. By playing files of this format on special equipment capable of reading this track, you can obtain surround sound that conforms to the Surround 5.1 standard.




/bitstream-binary-5807f60f3df78cbc28b94614-a90cf1c6655b4a29b047234bfcdf9892.jpg)