How does encoding work in digital audio? Part 5
DSD offers significant advantages over PCM:
/bitstream-binary-5807f60f3df78cbc28b94614-a90cf1c6655b4a29b047234bfcdf9892.jpg)
more precisely draw a wave;
increased immunity to noise;
an easier way to change and transmit a digital stream;
In theory, it is possible to reduce cost by simplifying DAC circuits, but due to backward compatibility, manufacturers are unlikely to do so.
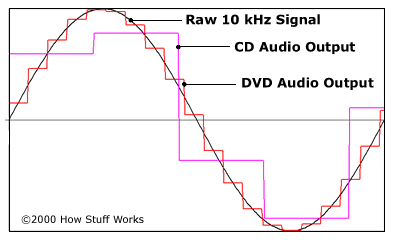
Originally, SACDs used the DSD x64 format with a sample rate of 2822.4 kHz. The 44.1 kHz audio CD sample rate was taken as the basis, increased 64 times, hence the name x64. The following DSDs are currently in use:
x64 = 2822.4 kHz;
x128 = 5644.8 kHz;
x256 = 11,289.6 kHz;
x512 = 22,579.2 kHz;
declared DSD x1024.
DXD
There is a certain intermediate format between PCM and DSD called DXD – Digital eXtreme Definition. This is, in fact, high definition PCM: 352.8 kHz or 384 kHz with 24 or 32 bit quantization. It is used in studies for the processing and subsequent mixing of materials.
But this approach is flawed: firstly, it does not allow to use all the advantages of DSD, and secondly, the file size is larger than in DSD. At the moment, flagship DACs on the I2S input accept a PCM data stream with a sample rate of up to 768 kHz and a bit depth of up to 32 bits. It’s scary to even consider how much hard drive space an album will take up at this resolution.
DSD has practically separated from SACD. Now, the DSD format can often be found packaged in files with the DSF and DFF extensions. Many turntables have been released with the ability to record in DSF and DFF, lovers of good sound are increasingly digitizing vinyl records in the DSD format. But in recording studios, nobody wants to invest in unpopular formats, so they continue to rivet the sound with a minimum wage: 44.1 × 16.
DSD switching and data transmission
To transfer a digital transmission to DSD, a three-pin connection scheme is used:
DSD Clock Pin (DCLK) – sync;
Data input pin DSD Lch (DSDL) – left channel data;
Data input pin DSD Rch (DSDR): Right channel data.
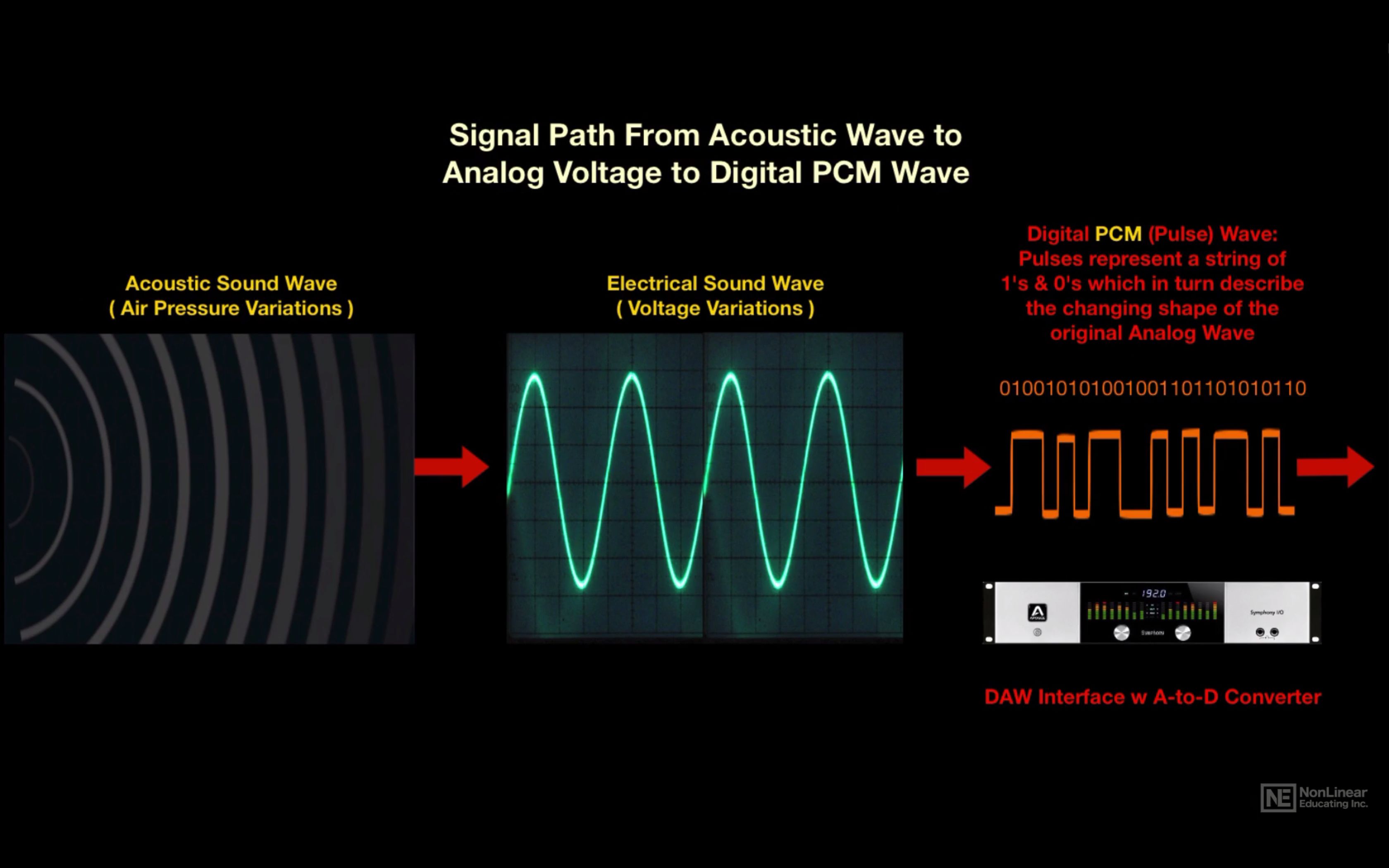
Unlike I2S, DSD data transmission is extremely simplified. DCLK sets the clock rate of the bit sync, and the left and right channel data is transmitted sequentially through the DSDL and DSDR pins, respectively. Here there are no adjustments, recording and playback in DSD is done little by little. This approach provides the closest approximation to the analog signal, and due to the high frequency, the quantization noise is reduced and the reproduction precision is increased by an order of magnitude.
PDO
DoP is often used to carry DSD data streams, so it’s worth mentioning. DoP is an open standard for transferring DSD data over PCM frames (DSD over PCM). The standard was created to transmit a stream through controllers and devices that do not support direct DSD streaming (not native DSD).
The principle of operation is as follows: in a 24-bit PCM frame, the upper 8 bits are padded with ones; this means that DSD data is currently being transmitted. The remaining 16 bits are sequentially filled with DSD data bits.
For x64 DSD transmission with a single bit rate of 2822.4 kHz, a PCM sample rate of 176.4 kHz (176.4 x 16 = 2822.4 kHz) is required. For DSD x128 transmission at 5644.8 kHz, a PCM sampling rate of 352.8 kHz is already required.