MP3 and audio digitization.

All of humanity has become accustomed to such everyday things as recording and reproducing sound, be it a voice recorder, an answering machine, or musical recordings of their favorite artists. And people who spend most of their time near the computer probably can’t imagine life without sound. This article will focus on such a common encoding format as MP3.
Well, Thomas Alva Edison started recording when he yelled the words “Mary had a lamb” on his “Talking Machine”. The “talking machine” was the world’s first device to record and reproduce sound: a phonograph that mechanically recorded a soundtrack on a wax roller. At the time, this was certainly a huge step forward, as at that time, and this was in 1877, no one came up with the idea of creating something similar.
However, the biggest disadvantage of this sound carrier was the fragility of the recording. With the development of science and technology, people learned to record sound not only mechanically, as Edison did, but also electromechanically and photoelectrically, and with the advent of computers, it became possible to record sound in digital form. The main advantage of this recording method is the preservation of sound quality, regardless of how many times it has been played or rewritten, and since digital information can be processed on a computer, this opened wide doors of possibilities for working with sound. . But since in the early stage of digital sound development, recording a composition cost a lot of disk space and magnetic media had a small capacity, software developers began to baffle the fact. how to put a lot of music on a small hard drive. This led to the appearance of various programs – compressors, which reduced the size of the audio file. Compression algorithms provided the removal of certain frequencies, which led to a loss in sound quality, and then the user was faced with the choice of spending money buying additional megabytes and storing uncompressed music files, or saving money. and use compressors.
First, let’s find out what “sound” is in real life. The transmission of information at a distance using acoustic vibrations is only possible due to the properties of the acoustic environment in which these same sound vibrations occur. They are possible due to the presence of elastic bonds between particles in the conductive medium. The sound source creates an area of pressure by compressing air molecules. These molecules transfer their energy to others that are nearby, and these, in turn, to others, etc., which leads to the appearance of areas of increased and decreased pressure in relation to the ambient pressure. This creates a sound wave that is continuous in nature. One of the parameters of the wave is amplitude. Let’s take a simple example: a guitar string. Everyone knows that to increase the volume of the sound it is necessary to pull the string with more force, thus increasing the amplitude of its vibration, which will lead to an increase in the pressure deviation. But a wave is not enough to transmit a sound that can be perceived by the human ear. Another important point is the vibration frequency, that is, the frequency with which the sound source creates a pressure change, and it is this frequency that determines the pitch of the transmitted sound. On a guitar, to change the pitch, you need to hold down the string at a certain fret, that is, change the length of the string and, as a consequence, the frequency of its vibrations. Another important point is the vibration frequency, that is, the frequency with which the sound source creates a pressure change, and it is this frequency that determines the pitch of the transmitted sound. On a guitar, to change the pitch, you need to hold down the string at a certain fret, that is, change the length of the string and, as a consequence, the frequency of its vibrations. Another important point is the vibration frequency, that is, the frequency with which the sound source creates a pressure change, and it is this frequency that determines the pitch of the transmitted sound. On a guitar, to change the pitch, you need to hold down the string at a certain fret, that is, change the length of the string and, as a consequence, the frequency of its vibrations.
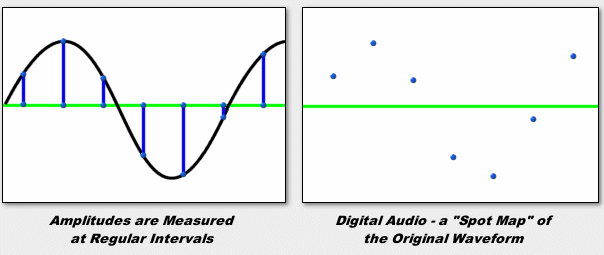
Now that we understand the nature of sound a bit, let’s move from analog to digital. To digitize “natural” sound, you must first convert it to an analog electrical signal. In this case, the analog of the amplitude of the sound wave is the amplitude of the voltage change. As mentioned above, the wave and the analog electrical signal are continuous functions, but for digitization they must be represented in discrete form. For this, an ADC (analog-digital converter) is used, which breaks the continuous wave into sections (Sample) and represents the amplitude of the wave in these sections as a number, that is, it quantifies. It is clear that for greater precision and purity of sound, the number of samples must tend to infinity and their size must go to zero. The number of samples per second is called the sample rate or sample rate and is measured in Hz. The question arises, what sample rate to use when digitizing so that the result is the most natural? It is theoretically known that for the most accurate reconstruction of a continuous analog signal from discrete values, it is necessary to use a sampling frequency at least 2 times higher than the frequency of sound (Nyquist’s theorem). It is known that the human ear can perceive sounds with a frequency of 18 to 20,000 Hz. Therefore, the optimal sampling frequency is 40 kHz or more. The most common sampling frequencies are 44.1 kHz, 48 kHz. However, due to the fact that harmonics above 20 kHz also affect the overall sound, encoders with sample rates of 96 and 192 kHz are also used. Also, the sound quality depends on the number of digits used to record the measured amplitude. The quantization error is inversely proportional to the bit width. Therefore, with 8-bit quantization, the sound level is recorded using numbers in the range [-128; 128], with 16 bits from [-32768; 32768]. For example, when recording audio CDs, exactly 16-bit quantization is used, so they have high sound quality.
Let’s make a middle conclusion: the ADC converts the analog signal into numbers and writes them as a sequence. Then comes Wave, a sound format. Note that audio CDs record sound in the same format. However, this storage method is not economical. Many people probably prefer an MP3 disc, which can contain more than 200 songs, than a regular CD. It does this by compressing the Wave file at the expense of quality. But don’t be alarmed, as the human ear is virtually incapable of recognizing the loss of sound quality after compression. Let me explain now. It all started when, in the late 1980s, the International Organization for Standardization (ISO) created the Moving Pictrures Experts Group, whose task was to develop an international standard for the presentation of digital video and audio data. The result of the group’s work is the MPEG-1 Layer 3 format, or MP3 for short, which compresses audio data by 1/12 with virtually no loss of quality. The audio compression algorithm in this format is based on the psychoacoustic characteristics of the human hearing organ, and therefore the removal of elements that are not perceived by the ear does not affect the noticeable deterioration in quality. Suppose there are many people in the room and they are all talking to each other at the top of their voices, and if you try to call a person who is only a few feet from you without raising your voice, don’t expect them to answer your call. , since due to the noise generated, it will not hear you. This is because sounds of the same frequency with higher amplitude mask other frequencies with lower amplitude. However, this unfortunate effect is happily used to compress digitized audio. The wave stream will contain all sound information, even masked, that is not audible to the ear, but after compression this information will be removed, reducing the file size. Another important characteristic of the human hearing organ used for compression is inertia. The ear, to put it vulgarly, is an inertial device, therefore, at the limit of the difference in sound level from highest to lowest for a certain time (~ 100 ms), a person cannot hear a sound of lower amplitude Therefore, the sound in this period may not be saved. It is also possible not to save the sound that is beyond the sensitivity threshold, that is, the sound level of which is below a certain value and is therefore inaudible to a person. Another interesting property used for encoding (but not by ”
Together, therefore, all of this leads to significant savings in the disk space occupied by the audio file. An average music file that occupies 30-40 MB in “full” form, after encoding it in MP3, already occupies 3-4 MB, allowing you to record more than 11 hours of music on a disc. However, this is not the limit. In 2001, the MP3 format had a successor: the MP3Pro format. Its creators are Thomson Multimedia and the Fraunhofer Institute in Germany. A distinctive feature of the new improved format is that, with the same quality, the files in the new format take up 2 times less space compared to normal MP3s. For example, an MP3Pro file with 128 kbps sound quality will be the same size as a 64 kbps MP3 file. Another advantage is
Let’s see how this is achieved. The working principle of the MP3Pro format is quite simple. When encoding, the audio stream is divided into two parts, two streams. The first is the low-frequency one, which is encoded in the usual MP3 format, which, by the way, makes the formats backward compatible, because normal players only play this part of the file. The second stream is high frequency, which is encoded in the part of the MP3 stream that older players ignore. The new decoder combines these two streams, leading to full sound across the entire frequency band.
Regarding the promotion of the new format in the market, compared to its older brother, MP3Pro has not received such a wide distribution. Thomson Multimedia offers a free version of the MP3Pro Player / Encoder for download from their website. The limitations of this version are that only 64 kbps quality is available for encoding. WinAmp lovers have a plugin to play MP3Pro files
Of course, the light did not converge on MP3, there are other digital encoding formats, but despite this, it is still the most popular.