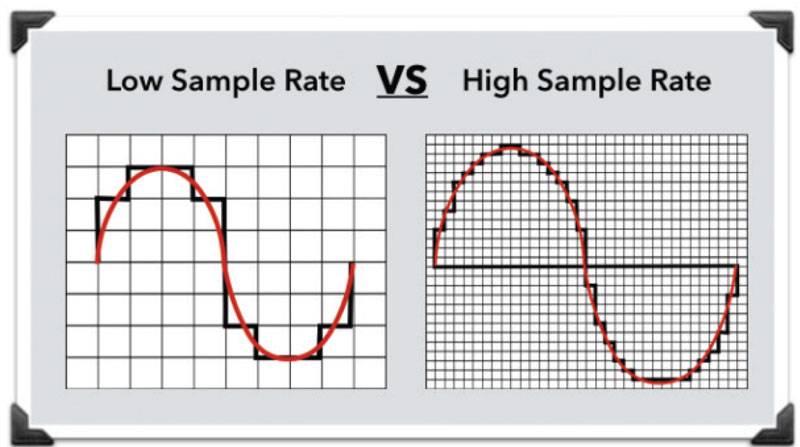
Why upsampling? Part 2
For every doubling of the sampling frequency, the spectral density of the noise is reduced by half and the signal-to-noise ratio increases by 3 dB. Since the resolution limit for the pressure level is approximately 1 dB, these decibels are unlikely to have a noticeable effect on sound perception in the high-frequency region. Based on these numbers, it is absolutely impossible to draw tentative conclusions about the change in sound quality.
In order to relate the spectrum of quantization errors, sampling frequency and sound quality, in this article it is proposed to use a tonal signal as a music model, as is usual to evaluate the quality of sound paths. This approach relies heavily on materials published in the “Sound Engineer” magazine.
The results can be summarized as follows. Unlike analog audio, digital audio is the product of amplitude modulation. This is manifested in a rigid functional dependence of the quantization error spectrum of the frequency multiplicity factor of the audio signal F and the sampling frequency fs, represented as the ratio of prime numbers y and x (k = fs / F = y / x). The frequency spectrum of quantization errors is always discrete and is determined solely by the multiplicity factor; the components of this spectrum are also determined solely by the amplitude of the audio signal, expressed in quanta. This means that the mechanism for shaping the quantization error spectrum does not depend on the number of bits used. With an increase in the quantization bit depth, the spectrum does not change in shape and composition, but only changes in level by 6 dB with each additional digit. (There are situations where a change in bit depth leads to a change in spectrum, – Ed.) The auditory perception of the quantization error spectrum is largely determined by the frequency response of hearing, which, in turn, it depends largely on the sound pressure level.
The frequencies of digital sound are divided into multiples when x = 1 and submultiples when x> 1. At multiple frequencies, the spectrum of quantization errors is harmonic and the main pitch is the frequency of the audio signal. If y is an even number, then the spectrum contains only odd harmonics. If y is an odd number, then the odd and even harmonics of the audio signal are present in the spectrum.
At multiple sub-frequencies in the quantization error spectrum, the components appear below the frequency of the audio signal, down to zero, and the lower limit of the spectrum Fn (x) is determined by the formula x – Fn (x) = F / X. In this case, the frequency Fn (x) becomes the fundamental pitch of the sound for quantization errors, and all other components, including the frequency of the sound signal, are converted to its harmonics. If the number is even at the submultiple frequency yskr, then the spectrum contains only odd harmonics of the frequency Fn (x). If yskr is an odd number, then the spectrum contains odd and even harmonics of this frequency. Low-frequency components in the quantization error spectrum lead to the appearance of harmonics in the form of pitch or consonance. They are especially noticeable at high frequencies in the audio signal when there is no frequency masking effect.
To clarify, we will give an example of a quantization error spectrum at an audio signal level of minus 30 dB with 8-bit quantization. Let fs = 48 kHz and F = 12800 Hz, then the multiplicity factor k skr = y / x = 48000/12800 = 15/4 and therefore the lower cutoff frequency Fn (x) = F / x = 3200 Hz, and the spectrum consists of odd and even harmonics of this frequency.
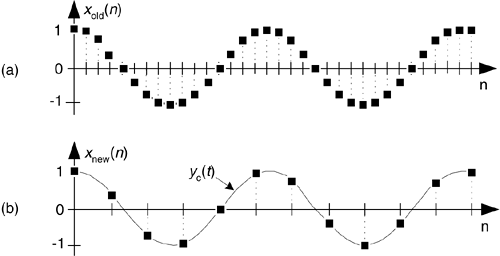
1.jpg
Figure 1. Quantization error spectra at submultiple frequency deviation
When the frequency of an audio signal deviates from a submultiple value by a small amount, sidebands appear around all harmonics of the spectrum, including zero (Fig. 1a), the number of spectrum components increases dramatically, and the limit bottom of the spectrum decreases, since the current value of x increases a lot.
Suppose, for example, that the frequency increment of the audio signal is 1 Hz, then the value of the multiplicity factor k = y / x = 48000/12801 = 16000/4267 and the lower limit frequency of the deviation spectrum becomes Fno = 12801/4267 = 3 Hz, and the interval between the components of the spectrum decreases to 6 Hz (Fig. 1b).