Audio sample rate and bit depth – in simple, understandable language

What is the sample rate (sample rate)? What is bit depth?

Even if you are not dealing directly with digital sound recording, you will be interested!
Are you new to the world of digital music? Not sure what all these designations and complex numbers mean?
Hmm, no wonder! After all, every day there is more and more information. And knowing everything is almost impossible.
Yes, this is not necessary! You need to know the essentials.
Sample rate and bit depth are sound engineering concepts that you should know if you decide to make music in a computer environment.
Even if you haven’t had to record music in a virtual environment yet, but have dealt with audio (be it on a portable digital player, a player on a computer, or elsewhere), you may have seen some numbers in the properties of audio: “16 bit, 24 bit, 44100 Hz, 48000 Hz …”
The material is presented briefly and is accessible even to the uninitiated. Just the essentials.
So what are sample rate and bit depth? What is it for?
To begin with, we agreed that in different sources you can find: Sample rate and Sample rate. The abbreviations are equivalent. Call it what you like the most.
And bit and bit depth. It’s the same, the same, it just sounds different.
So.
Sample rate (sample rate) …
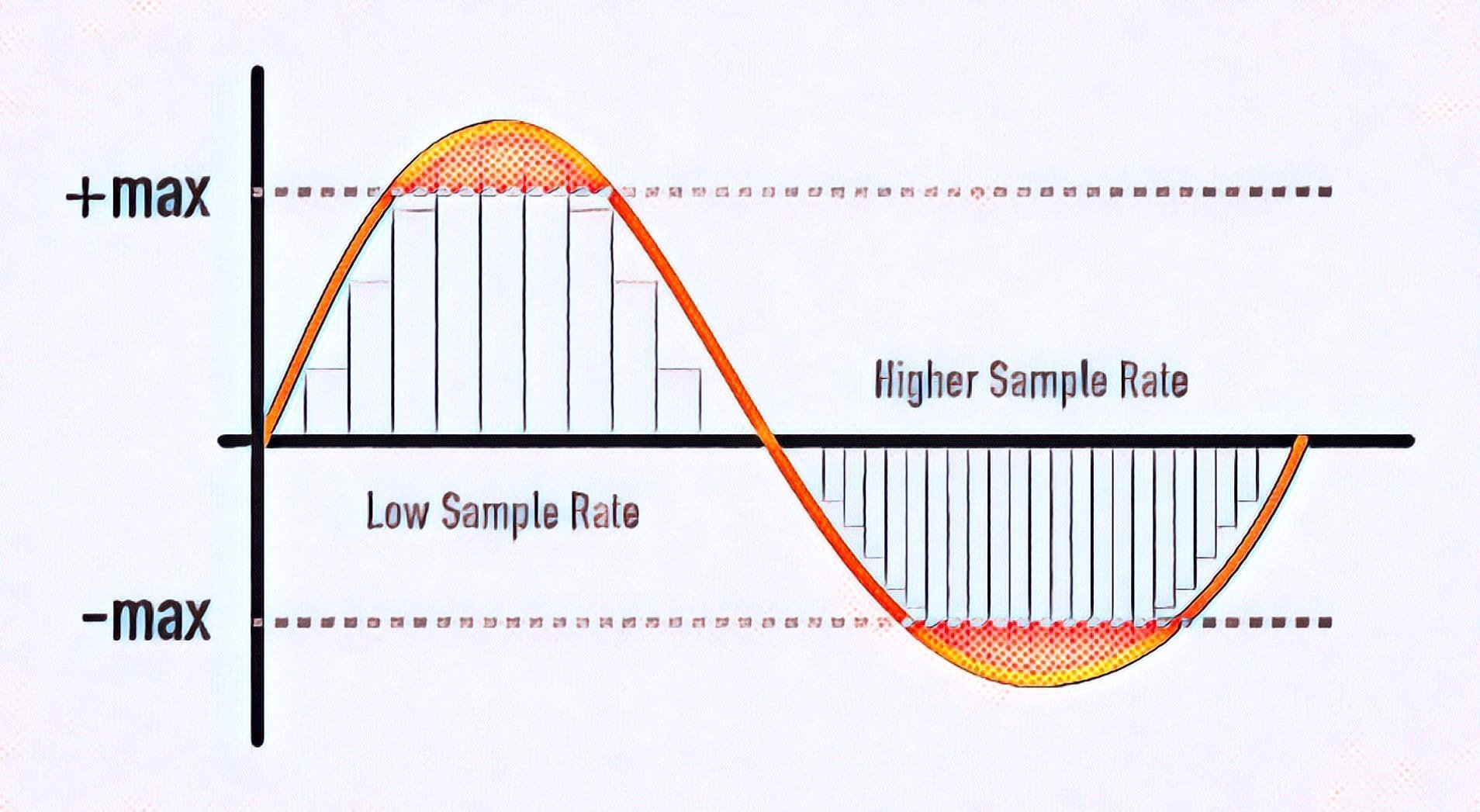
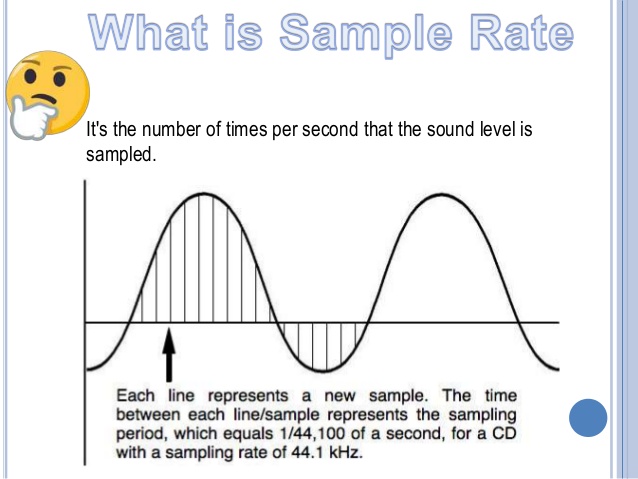
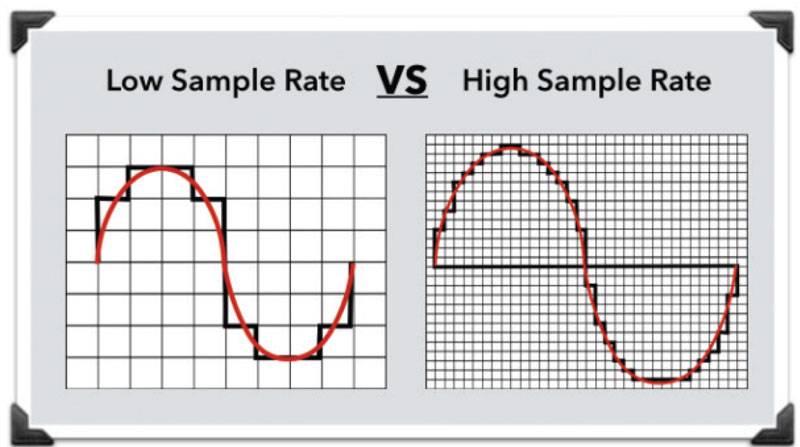
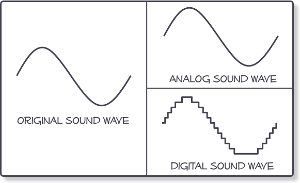
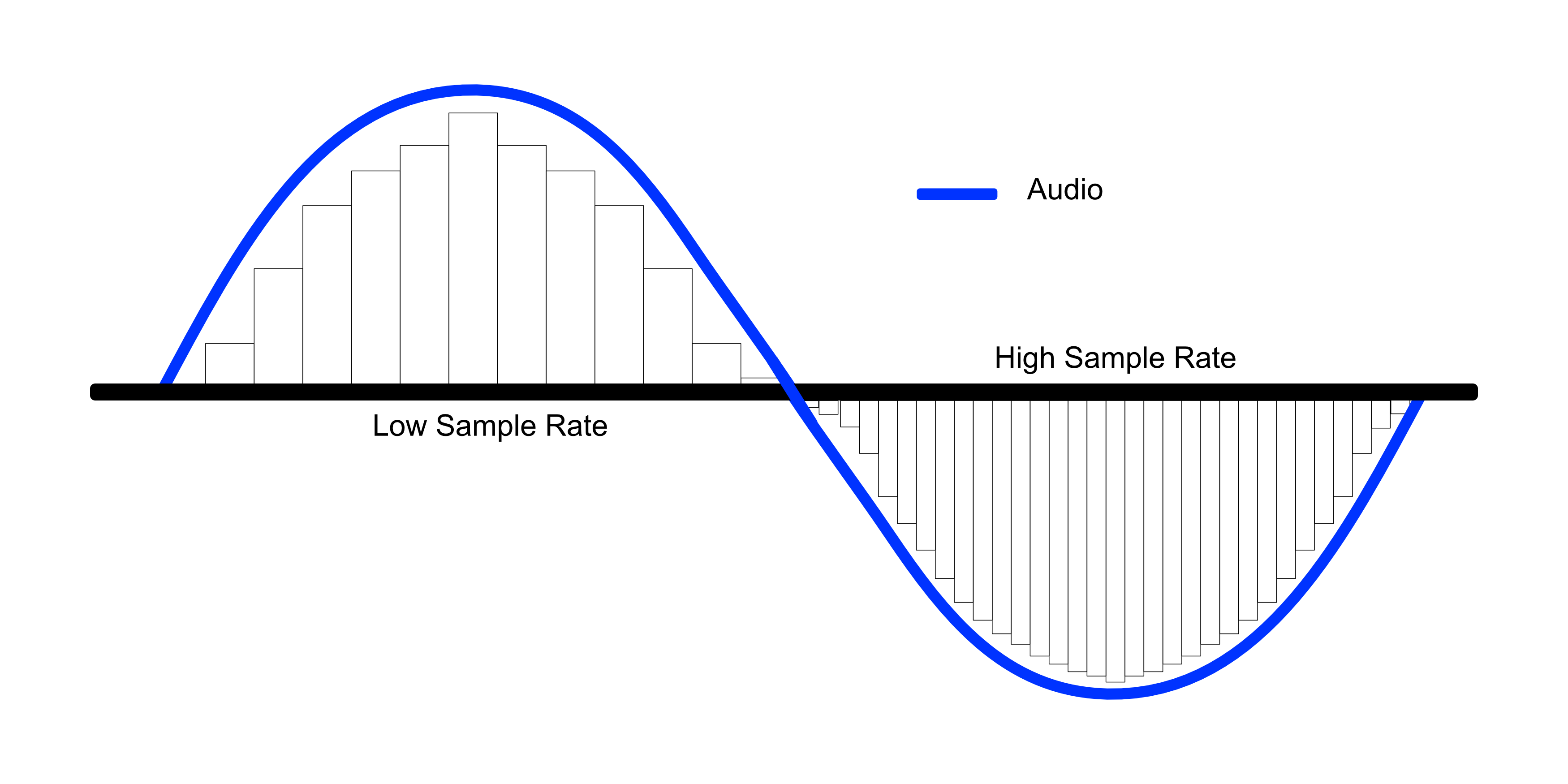
All inanimate music (music produced by a computer, music center, etc., that is, not live) has this parameter. This is the number of samples per second. Without going into details, I will say that 44100 Hz is optimal for humans. Since at a higher value, the sounds to be sampled will be practically inaccessible to our ears, we will simply not hear them, because they will be out of earshot.
I’ll explain a bit more in datell about sample rate. Discrete means discontinuous. That is, the sampling process is the processing of each bit of information one by one (that is, discretely and not all at once). In our case, this happens 44100 times per second. By Nyquist’s theorem, the required sampling rate for normal perception should be twice the hearing threshold. Since an average person listens up to 16 KHz (KiloHz or 16000 Hz), and something (normal for a healthy young person) up to 20 KHz, the sampling frequency was determined at 44.1 KHz (44100 Hz), that is, twice the threshold. audibility of the human ear. Why not 40 kHz (40,000 Hz)? Taken with margin (nobody canceled errors and noise on the route and after the CD release).
I hope everything is clear now.
The bitness (Bitness) is a kind of resolution of these same samples. Why am I calling this permission? Just so you prefer to understand by analogy what is what.
Grab your monitor – the higher the resolution, the better the picture, right? At low resolution you will see individual pixels and the eye will no longer be happy as before. I smile
Bitness is dynamic range, that is, the oscillation of your audio up and down (in terms of volume, power, so to speak), the nuances of performance.
The higher the audio bit rate, the more space the audio will occupy on your hard drive (on your computer); keep in mind.
For projects that are important to you, I advise you to use 24 bits and a sample rate of 48000 Hz. THIS IS A STANDARD. Then, for CD output, it will be possible to downgrade the data to 16 bits and 44.1 kHz.
But some people prefer to work on 24/96 (24 Bits – bit depth, 96 KHz – sample rate) or 24 / 88.2. The taste and the color …
For most projects, 16 / 44.1 is adequate (16 bit – bit depth, 44100 Hz is equivalent to 44.1 KHz – sample rate).
The sample rate and bit depth go directly next to each other and never go alone. That is their destiny.