MP3 – Compression criteria
To perform such compression, the MP3 format is based on a simple concept: filter a digital piece of music and eliminate all unnecessary information, thus reducing space.

The human ear is an almost perfect instrument but it also has its limits. The human ear pass band extends from 20 Hz to 20,000 Hz, but is much more sensitive to those in the midrange, 700 to 6,000 Hz, where most of the information is concentrated.
The study of auditory perception is a matter of psychoacoustics that mainly analyzes 2 factors that are later used in MP3 encoding:
Mp3 – Auditory perception
In the area of sounds, only a few can be heard by the human ear. The following figure shows these areas that represent the different sound frequencies. Only those in the white area are audible from our ear.
The sounds that the ear perceives are only those of the white areas
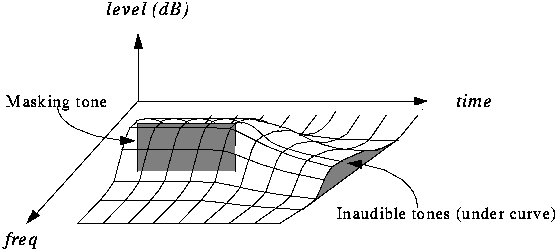
Masking
Masking is nothing more than the superposition of weak sounds with loud sounds. It almost always happens that the sounds of different instruments overlap each other. In cases where the loudest sound completely covers the lowest, there is a so-called masking. In MP3 files, masking allows you to remove the information from the weakest sounds, which, however, because they are not perceived by the ear, are virtually irrelevant.

MP3 – The Name
The name MP3 comes from the MPEG standard, which means Moving Picture Experts Group. This group was created specifically for the development of systems and standards used in video compression. DVD movies and satellite broadcasts (DBS) use the MPEG standard to efficiently compress video information.
MPEG compression includes a subsystem for sound compression with three different compression levels (layers) depending on the quality of the information. Layer-3 is the one used for the MP3 standard, which stands for MPEG Layer-3.
MP3 – Step by step compression
The MP3 Encoder is that program that analyzes the uncompressed digital file (for example, a Wav file) and transforms it into an MP3 file.
The audio signal is filtered and divided into 576 areas (called subbands) through a process that uses DCT (Discrete Cosine Transformation) and manages to eliminate all unnecessary frequencies. The human ear, as already said, perceives sounds only beyond a certain threshold so that all the audio below is not encoded.
At this point, the resulting signal is passed through the psychoacoustic model in which the masking thresholds of which we spoke earlier are identified. This is done using Discrete Fourier Transformation (DFT).
During the masking of the 576 subbands, the frequencies to be masked are determined and therefore can be removed.
After masking, the defined Stereo Ensemble process is applied. Below a certain frequency, the ear cannot perceive the spatial position of the sounds, so they can be recorded on a single channel (therefore, in mono format) with significant space savings.
Once the file is ready, the data is re-analyzed and compressed using Hufmann encoding which enables a data reduction (without loss of information) of approximately 20%.
At this point, after all the data has been collected, the encoder proceeds to create the bit stream that will form the final MP3 file.