To be able to store large amounts of data, a huge amount of storage space is required. When the space is at some point full, a new storage space is usually made available. Mainly in the form of new hard drives, server systems or the like. But there is another way to store more data: data compression.
Data compression works like a pillow you squeeze
Figuratively speaking, data compression works the same way as when you squeeze a pillow. Not all air is required between the pillowcase and the feathers. By squeezing the pillow, you compress it by removing the air (as much as you can); the pillow becomes smaller, that is, more compressed than before.
It is similar with data compression. Here also items that are not absolutely necessary, in this case data, are removed and the storage space still required by the remaining data is reduced.

Different lossless compression encoding methods.
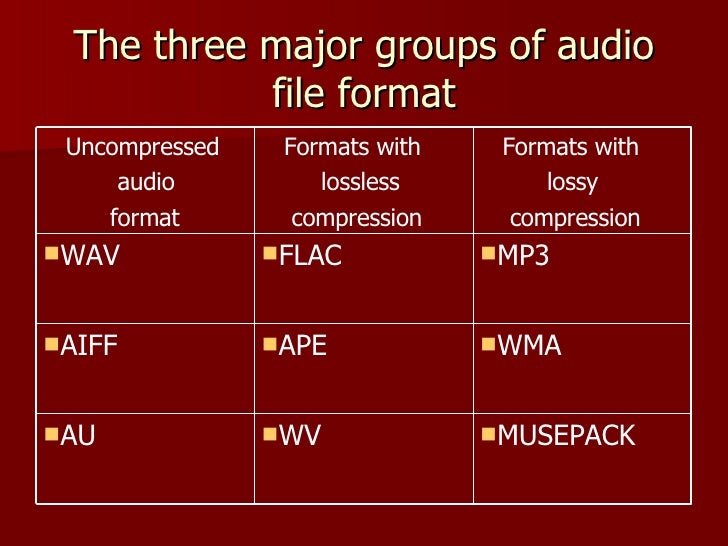
When it comes to data compression, a distinction is made between lossless compression and lossy compression, so it can be further subdivided into different types of compression.
Lossless compression is generally only done with text files. If the text is saved as a character string and not as an image or the like, the storage space can be saved using the dictionary method, for example. Recurring parts of the string are simply replaced by abbreviations.
Text: Hello world. Hello user
Encoding: world X5. X5 users.
With the help of Run Length Encoding (RLE), identical text components that are placed one after the other are only saved once. This can also save storage space.
Text: Today was beautiful, beautiful, beautiful and tomorrow will be more beautiful.
Coding: Today was / 3 / beautiful, / and tomorrow will be more beautiful.
In entropy encoding, as is the case with Huffman code or arithmetic encoding, for example, text elements are sorted in binary and encoded according to their frequency, and the most frequently occurring element is given the binary number smaller.
With these numbers, the text elements are stored in a separate dictionary.
Text: IF YOU FLY BACK, FLY, FLY, FLY, FLY AFTER.
Coding: 10100 1 1 1101 1 1 1 11
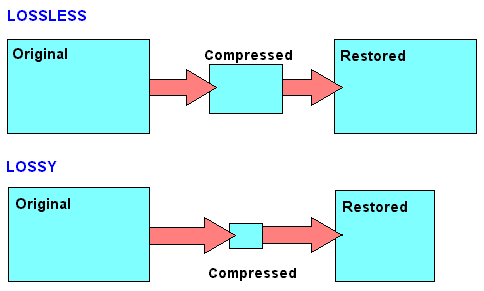
Difference between lossless and lossy compression
The benefit of lossless encoding is clear: it ensures that all “compressed” data in the compressed data packet can be accessed and restored.
In addition to lossless compression, there is also lossy compression. Irrelevant information is not encoded here, but is directly removed. Therefore, we speak of a reduction in irrelevance.
Lossy compression: the MP3 format
Of course, this procedure can lead to extremely high compression rates. However, this irrelevant information is irrevocably deleted. This means that the original state cannot be restored after compression.
Lossy compressions are often used for image, audio, and video files, as they often have to handle large volumes. The MP3 format is a classic example in this context. Here, frequency patterns are removed from an audio file that are almost inaudible to the human ear. This saves storage space.
If you compress data packets, you can use your own data storage capacity better than uncompressed data packets. However, you should always consider the type of compression you are using. Because lossy compression is not always desirable.