Digital audio compression

The concept of loudness is close and understandable not only for a musician, but also for people who are not associated with music. The relationship between the volume of the parts of a piece and the volume of the instruments that are playing simultaneously is called the dynamic range. One of the main tools producers and musicians use to influence dynamic range is the compressor.

Although the compressor works with a known phenomenon, loudness, in most cases its use occurs spontaneously, randomly, without understanding the essence of what is happening. You can know the general principle of the compressor and the purpose of each handle, but this does not eliminate the stupor at the first experience.
Why do you need a compressor?
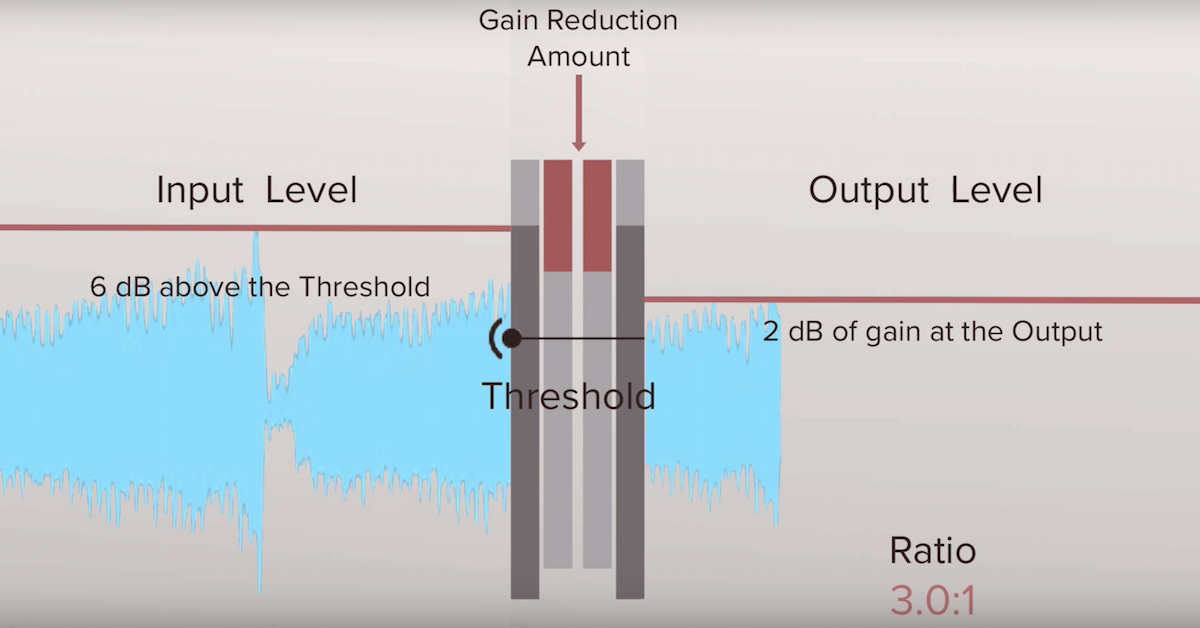
The main purpose of the compressor is to automatically change the signal level. It works roughly the same as if you kept your hand constantly on the volume fader, turning it up and down. The difference is that a compressor can react very quickly to changes, much faster and more accurately than a human.
Up to this point, the word compressor meant a whole class of dynamic devices. Using the same basic principles as a conventional compressor, various instruments work for different purposes: limiters, expanders, gates, etc. They are united by working with the volume of individual sounds or the mix as a whole.
The classic compressor is controversial by its very name. Everyone knows that he makes the loudest sound. But the name comes from compress, which means “compression”, and if you ask any sound engineer what a compressor does, you’ll hear the answer: “squash the signal.” The compressor reduces the amplitude of the dynamic bursts, makes them quieter. So what is the main purpose of the compressor: to make it quieter or louder? The answer is both at the same time.
Let’s take an example of voice recording. Very often, in the process of singing, syllables or sounds of different volume are heard. If the singer does not control the dynamics of his performance very well, then such differences create problems for the sound engineer and negatively affect the final result of the work. Silent syllables disappear into the mix, text becomes difficult to distinguish, and if you adjust the volume for a quiet area, in other places the voice begins to “stand out.”
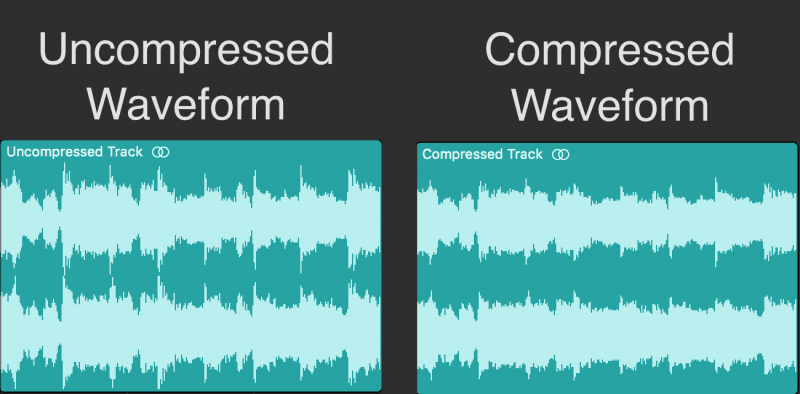
This is where the compressor comes in. It allows you to suppress strong bursts, equalize them with silent fragments. Now you can turn up the volume of the track without fear of some syllables sticking out. So the compressor makes the sound lower and higher at the same time. Three images show the stages of working with sound: a source with large peaks (a), a compressed signal (b) and an increase in the volume level of the entire file (c).
It is especially important to apply compression when recording in a digital environment, when we are forced to adhere to a maximum level of 0 dB, because exceeding this threshold leads to clips and distortion. When clips appear, we lower the preamp level, which means we lower the volume of not only bursts, but quiet areas as well, leading to signal degradation due to quantization and aliasing noise.
The compressor, positioned between the preamp and the digital recording system, operates only on the loudest bursts, reducing their volume and ensuring a smooth soundtrack. Thanks to this, we have the opportunity not to reduce the overall volume of the recorded signal and to maintain the sound quality.
Unfortunately, many modern musicians, without going into the technical characteristics of the compressor, use it everywhere, believing that with its help you can “stretch” any sound in the mix. Also, compressors are often included on the road in extreme conditions. They are only used by experienced sound engineers when there is a real need.
The compressor helps avoid recording problems. The most common causes of problems can be the following:
Non-professionalism of the interpreter (dynamic unevenness).
Mismatched path (bad, mismatched, or inadequate microphones, preamps).
Disadvantages of the digital environment (limited to 0 dB).
Uncomfortable conditions for the singer (small and stuffy room, poor monitoring).
Low qualification of a recording engineer.
If a performer has a voice and can sing into a microphone, and a recording engineer knows her job well and knows how to properly position microphones and set up equipment, a compressor may not be required at all. But this is the ideal situation.