Hardware for processing digital audio – Part 2

4. Mixing unit. On sound cards, the mixing unit provides adjustment of:

signal levels of the line inputs;
MIDI input and digital audio input levels;
the level of the general signal;
panorama
doorbell.
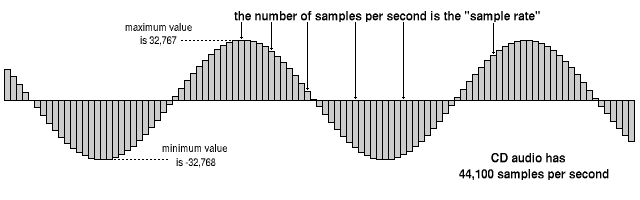
Let us consider the most important parameters that characterize sound boards and sound-music. The most important characteristics are: maximum sample rate in record mode and in playback mode, maximum sample rate or bit depth (maximum quantization level) in record and playback mode. Furthermore, since sound cards also have a synthesizer, the parameters of the installed synthesizer also refer to its characteristics. Naturally, the higher the quantization level that the card is capable of encoding the signals, the better the signal quality. All modern sound card models are capable of encoding a signal with a 16-bit level. One of the important features is the ability to simultaneously play and record audio streams. Function cards play and record simultaneously is called full duplex (full duplex). There is another characteristic that often plays a decisive role when buying a sound card: the signal-to-noise ratio (Signal-to-noise ratio, S / N). This indicator affects the purity of the signal recording and playback. The signal-to-noise ratio is the ratio between the signal power and the noise power at the output of the device; this indicator is generally measured in dB. A good ratio is 80 to 85 dB; ideal – 95-100 dB. However, it should be noted that the quality of playback and recording is strongly influenced by interference (interference) from other components of the computer (power supply, etc.). As a result, the signal-to-noise ratio may deteriorate. In practice, there are many methods to solve this problem. Some suggest grounding the computer. Others, to protect the sound card from interference as much as possible, “pull” it out of the computer case. However, it is very difficult to completely protect yourself from interference, as even the map elements themselves are created by floating above each other. They are also trying to fight this by filtering every item on the board. But no matter how much effort is made to solve this problem, it is impossible to completely eliminate the influence of external interference.
Another equally important characteristic is the non-linear distortion coefficient, or total harmonic distortion, THD. This figure also critically affects the clarity of the sound. The non-linear distortion coefficient is measured in percentage: 1% – “dirty” sound; 0.1% – normal sound; 0.01%: pure Hi-Fi sound; 0.002% – High Fidelity Sound – Hi-End .. Non-linear distortion is the result of inaccuracy in restoring the signal from digital to analog. Simplified, the process of measuring this coefficient is carried out as follows. A pure sine signal is supplied to the input of the sound card. At the output of the device, a signal is taken, the spectrum of which is the sum of the sinusoidal signals (the sum of the original sinusoid and its harmonics). Then, using a special formula, the quantitative ratio of the original signal and its harmonics obtained at the output of the device is calculated.
What is a MIDI synthesizer? The term “synthesizer” is commonly used to refer to an electronic musical instrument in which sound is created and processed, changing its color and characteristics. Naturally, the name of this device comes from its main purpose – sound synthesis. There are only two main methods of sound synthesis: FM (frequency modulation) and WT (wave table). Since we cannot dwell on them in detail here, we will describe only the main idea of the methods. FM synthesis is based on the idea that any oscillation, even the most complex, is essentially the sum of the simplest sinusoids. Thus, it is possible to superimpose signals from a finite number of sinusoid generators and, by changing the frequencies of the sinusoids, obtain sounds similar to the real ones. Wavetable synthesis is based on a different principle. Sound synthesis using this method is achieved by manipulating the prerecorded (digitized) sounds of real musical instruments. These sounds (called samples) are stored in the permanent memory of the synthesizer.