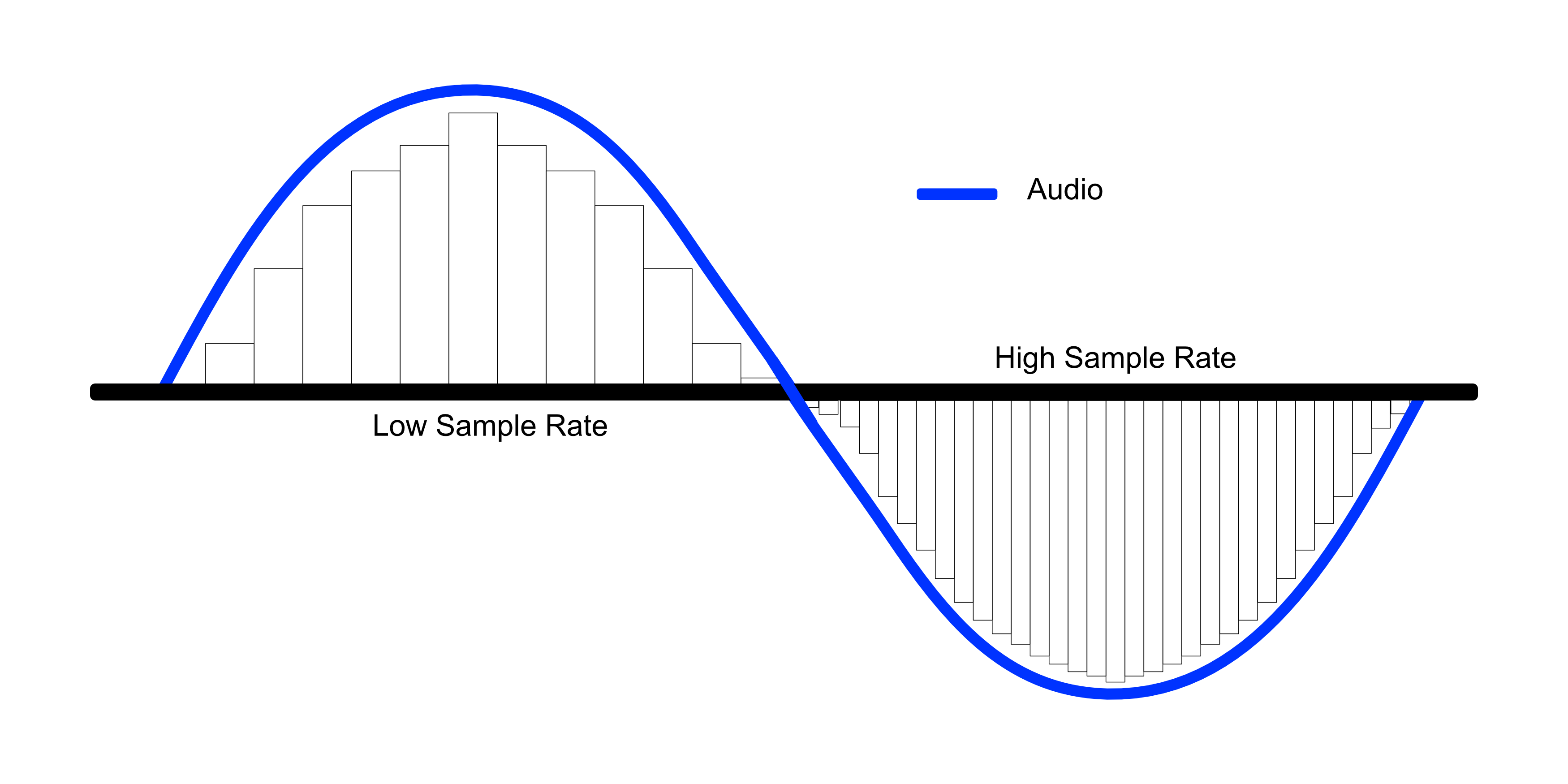
Sample rate, where it comes from

Where does the sample rate for CD-audio 44100 hertz come from?
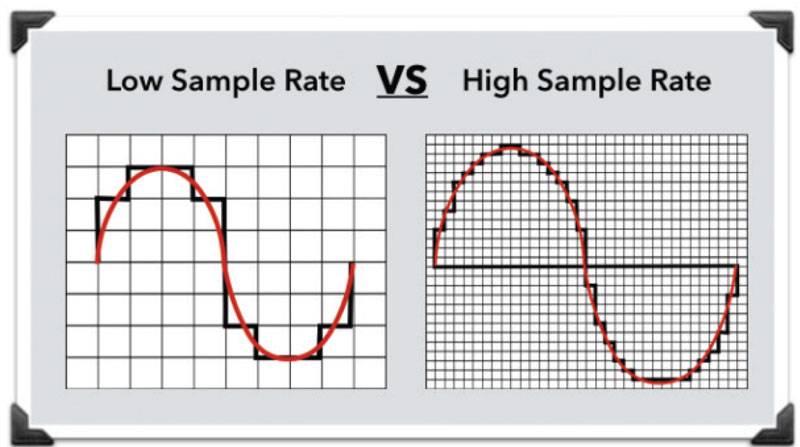
The standard sample rate for CD-audio is 44100 Hertz. Where and why were these 44100s originally chosen for CD audio production?
Starting from the condition (see Nyquist-Shannon-Kotelnikov) of reproduction of the upper limit of the spectrum at 20 kHz, the sampling frequency should have been chosen above 40 kHz. But at the time of the creation of these standards and the development of CD-DA technology (the second half of the 70s of the last century), there was no generally accepted medium in which to record, edit and store digital sound. And for this, it was decided to use standard VCRs, which in those days worked in U-matic format. The digital signal was encoded by a special encoder into a black and white video pseudo-signal and recorded on a video cassette. The structure of the digital signal had to be linked to the frequency and structure of the fields of the television signal used for recording.
This decision was complicated by the fact that different video recording standards are used in Europe and the US: 525 lines at 60 Hz and 625 lines at 50 Hz, while not all lines can be used to record information. The selected frequency should fit the structure of both video signals. 44100 Hz meet this requirement.
In a 60 Hz NTSC video signal, 35 lines are not used for recording, leaving 490 active lines per frame, or 245 in the field for digital audio recording. When writing three samples to a string, the sample rate will be:
60 × 245 × 3 = 44100.
In a 50Hz PAL signal, 37 lines are not used, leaving 588 active lines per frame, or 249 per field, so the frequency will be:
50 × 249 × 3 = 44100.
Although digital sound at that time had nothing to do with the video signal, video equipment was used in the production of the CD, which determined the choice of sampling frequency.