How digital compression works.

Have you ever wondered how sound is reproduced on digital devices?
How is a sound signal formed from a combination of ones and zeros? I’m sure I was thinking, since I started reading! But often, even professionals only have a general idea of the modern sound route. In this article, you will learn how the different formats appeared, what a digital-to-analog converter is, what types of DACs exist, and what determines the quality of sound reproduction.
PCM
As you know, in digital audio, almost any format, with rare exceptions, is recorded using a pulse code stream or a PCM stream – pulse code modulation. FLAC, MP3, WAV, Audio CD, DVD-Audio and other formats are just ways to package, “preserve” a PCM stream.
How it all began
The theoretical foundations of digital sound transmission were developed at the dawn of the 20th century, when scientists tried to transmit an audio signal over a long distance, but not by telephone, but in a rather strange way for that time.
By dividing the sound wave into small parts, it could be sent to the receiver in some kind of mathematical representation. The recipient, in turn, could restore the original waveform and listen to the recording. In addition, scientists were faced with the task of increasing the bandwidth of the “ether”.
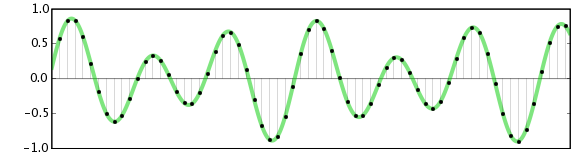
In 1933, the theorem of V.A. Kotelnikov. In Western sources, it is called the Nyquist-Shannon theorem. Yes, Harry Nyquist was the first to raise this issue: in 1927 he calculated the minimum sampling frequency to transmit a waveform, which later got his name “Nyquist frequency”, but Kotelnikov’s theorem was published 16 years ago before.
The essence of the theorem is simple: a continuous signal can be represented as an interpolation series consisting of discrete reports, from which the signal can be reconstructed. In order to roughly restore the original state of the signal, the sampling frequency must be at least twice the upper cutoff frequency of this signal.
For many years, the theorem was not in demand, until the advent of the digital age. It was then that it found a use. In particular, the theorem was useful when developing the CDDA (Compact Disc Digital Audio) format, in common people it is called Audio CD or Red Book. The format was released by engineers at Philips and Sony in 1980 and became the standard for audio CDs.
Format characteristics:
sampling frequency – 44.1 kHz;
quantization capacity – 16 bits.
INFO
The sampling rate is the number of signal samples taken during your sampling. Measured in Hertz.
Quantization bit: the number of binary bits that express the amplitude of the signal. Measured in bits.
The 44.1 kHz sampling frequency was calculated from Kotelnikov’s theorem. It is believed that the hearing of the average person cannot pick up sound beyond 19-22 kHz. The frequency was probably 22 kHz and was chosen as the upper limit.
22,000 × 2 = 44,000 + 100 = 44,100 Hertz
Where does 100 Hertz come from? There is a version that this is a small margin in case of errors or oversampling. In fact, Sony chose this frequency for its compatibility with the PAL transmission standard.
The bit depth of the CDDA format is 16 bits, or 65,536 samples, which equates to a dynamic range of approximately 96 dB. Such a large number of samples were not chosen by chance. Firstly, due to the strong influence of quantization noise, and secondly, to provide a formal dynamic range superior to that of the main competitors at the time – cassette records and vinyl records. I’ll cover this in more detail in the section on digital to analog converters.
The development of PCM continued on the principle of multiplying by two. Other sample rates appeared: first, the 48 kHz sample rate was added, and then the frequencies based on it were 96, 192, and 384 kHz. The 44.1 kHz frequency was also doubled to 88.2, 176.4, and 352.8 kHz. Bit depth increased from 16 to 24 and then to 32 bits.