Compression and compression methods of audio signals (types, differences, use)

Basics of the analog-to-digital conversion principle, sound conversion and compression method, existing sound storage formats. Programs to convert and process sound and audio files. Application of these programs in linguistic research.
Bit rate is the amount of information per unit of time. In general, the bit rate is the number of bits that we spend encoding a sound with a duration of 1 second.
Analog-to-digital converter (ADC): A device that converts an input analog signal into a binary code (digital signal). The reverse conversion is done using a DAC (digital-to-analog converter, DAC). Typically, an ADC is an electronic device that converts voltage into a binary digital code. However, some non-electronic devices with digital output must also be classified as ADCs, such as some types of angle-to-code converters. The simplest one-bit binary ADC is a comparator.
The circuit to convert an audio signal from analog to digital:
Sampling is the transformation of continuous images and sound into a set of discrete values in the form of codes.
Quantization is the process of aligning a set of musical notes to a grid.
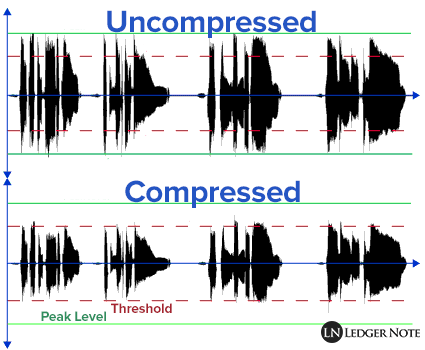
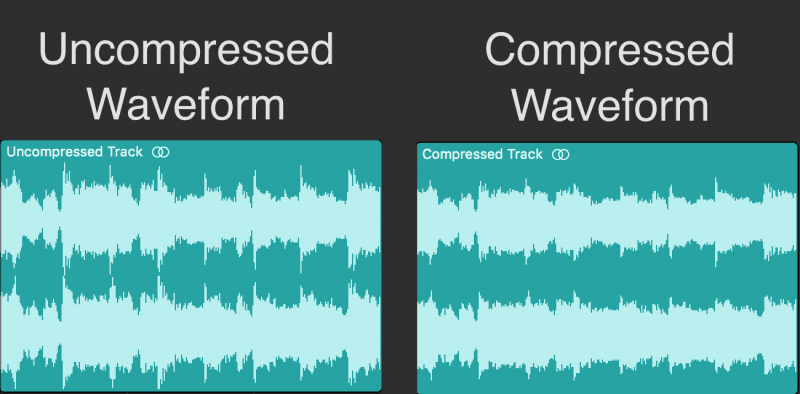
Compression (compression) of audio data is a process of lowering the bit rate by reducing the statistical and psychoacoustic redundancy of a digital audio signal.
The underlying idea behind all lossy audio compression techniques is to neglect the subtle details of the original sound that are beyond the reach of the human ear.
Codec (CoDec) is an abbreviation for compressor and decompressor. Basically, a codec is a collection of files, drivers, and libraries required to package a video or audio file into a compressed format and play the compressed file.
Formats:
AAC (Advanced Audio Coding) is an audio file format with less quality loss when encoding than MP3 of the same size. The format also allows you to compress without losing the quality of the source (ALAC AAC profile).
AAC (Advanced Audio Coding) was originally created as a successor to MP3 with improved encoding quality. The AAC format, officially known as ISO / IEC 13818-7, was released in 1997 as the new seventh part of the MPEG-2 family. There is also the AAC format known as MPEG-4
Apple AIFF: This file type is standard for Apple Macintosh systems and sound processing systems built on top of it. Apple AIFF stands for Audio Interchange File Format, an audio interchange file format, it is somewhat similar to WAV. Its peculiarity is that it allows you to place additional information along with the sound wave, in particular WaveTable samples (examples of the instrument sound together with synthesizer parameters), which improves the quality of the final result. Although today Apple computers are capable of playing files of almost any format, including MP3.
FLAC (Free Lossless Audio Codec) is a popular free codec for audio compression. Unlike lossy Ogg Vorbis, MP3 and AAC codecs, it does not remove any information from the audio stream and is suitable for both daily listening and archiving of audio collection. Today, the FLAC format is compatible with many audio applications.