Audio Compression (Format) Part 2
Lossy Audio Compression

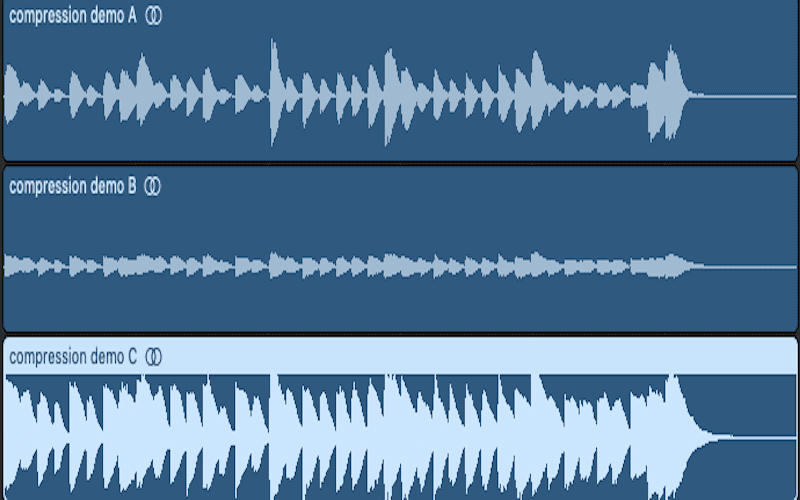
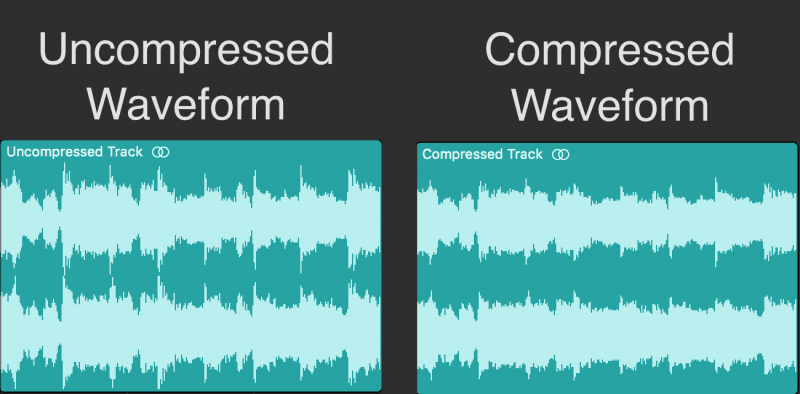
Lossy compression, which approximates some of the information in the original file to obtain a smaller file.
The compressed file size is 5 to 20 percent of the original size (lossless file compression is 50 to 60 percent of the original size).
Lossy compression is an irreversible process, but lossy compression takes into account human psychology and the recognition of the auditory system in the compression results.
So even though the compressed file is small, it is almost indistinguishable to the listener.
Due to the unrecoverable nature of lossy compression, this format is not suitable for jobs that require repeated archiving and reading.
For example, when a musician modifies the content of a piece of music, lossy compression is more suitable for the end user, and the most common lossy compression algorithm is MP3 .
The compression method commonly used for lossy data compression is Modified Discrete Cosine (MDCT), which uses the characteristics of the human hearing threshold and auditory masking to discard unimportant sound information.
Research that combines the auditory recognition of the human brain with the hearing threshold of the human ear is called acoustic psychology.
It is important to note that while lossy compression theoretically causes loss of the original file, this loss is not necessarily noticeable to the human ear. [1]