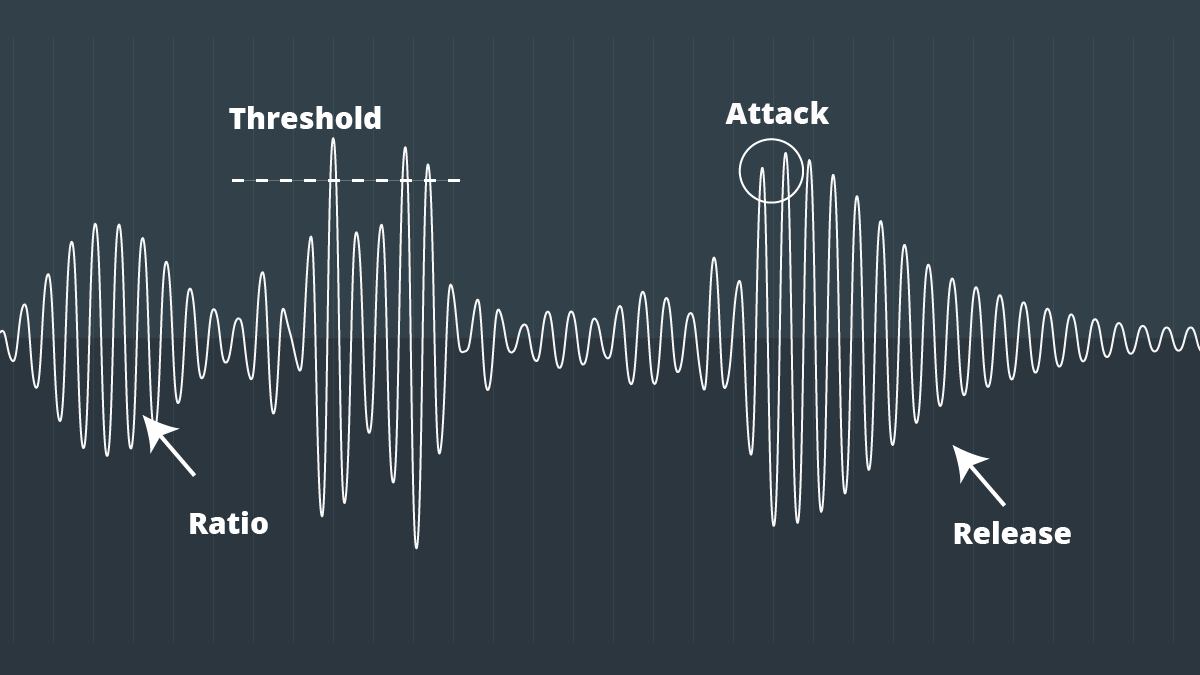
Compression encoding method Part 2
Other divisions of compression methods

In the field of audio compression, there are two compression methods, lossy compression and lossless compression. Commonly seen MP3, WMA, OGG are called lossy compression As the name suggests, lossy compression reduces the audio sample rate and bit rate, and the output audio file will be smaller than the original file. . Another audio compression is called lossless compression, which is what we’re talking about. Lossless compression can compress the volume of the audio file to a smaller size on the premise of saving 100% of all the data in the original file, and after restoring the compressed audio file, it can achieve the same size and same bitrate as the source file. Lossless compression formats include APE, FLAC, WavPack, LPAC, WMALossless, AppleLossless, La, OptimFROG, Shorten, while common and conventional lossless compression formats are just APE and FLAC. [1]
Main classifications and typical representatives of audio compression algorithms.edit streaming
Generally speaking, audio compression techniques can be divided into two categories: lossless compression and lossy compression, and according to different compression schemes, they can be divided into time-domain compression, transform compression, and time-domain compression. subband, as well as hybrid compression in which multiple technologies are combined with each other. Various compression techniques have large differences in algorithm complexity (including time complexity and space complexity), audio quality, algorithm efficiency (ie compression ratio), and codec delay. The applications of various compression techniques are also different.
Time domain compression technology (or waveform coding)
It directly processes the sample values of the audio PCM code stream and compresses the code stream through silence detection, nonlinear quantization, and difference. Common features of this type of compression technology are low algorithm complexity, average sound quality, small compression ratio (CD quality > 400kbps), and shortest codec delay (relative to other technologies) . This type of compression technology is generally used for voice compression, low bit rate (small source signal bandwidth) applications. Time domain compression technology mainly includes G.711, ADPCM, LPC, CELP, and block compression technology developed on these technologies, such as NICAM, Subband ADPCM (SB-ADPCM) technology.
Subband compression technology
Subband coding theory was first proposed by Crochiere et al. in 1976. The basic idea is to decompose the signal into the sum of components into several subbands and then adopt different compression strategies for each subband component according to its different layout features to reduce code rate. The usual subband compression technology and transform compression technology described below are based on the human perception model (psychoacoustic model) of the sound signal, and the quantization order of the subband samples or the samples The frequency domain is determined by analyzing the spectrum of the signal. other parameters are selected, so it can also be called perceptual compression encoding (Perceptual). Compared with time domain compression technology, these two compression methods are much more complicated. At the same time, the coding efficiency and sound quality are also greatly improved, and the coding delay is correspondingly increased. Generally speaking, the complexity of subband coding is slightly less than that of transform coding and the coding delay is relatively short.