
What is digital audio data compression?

It could be said that there are two methods with which it is possible to compress the data in the case of digital audio.
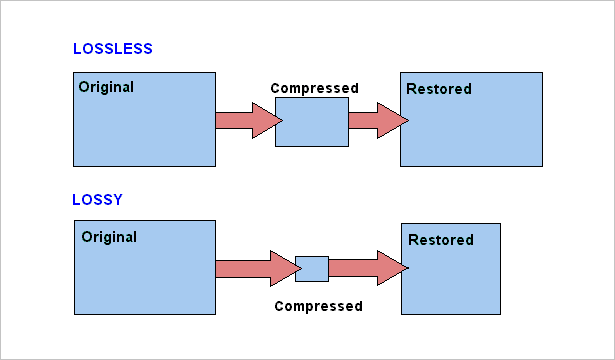
On the one hand, the method known as lossy compression is intended to reduce psychoacoustic redundancy and the other method is to reduce statistical redundancy. And this is known as lossless compression.
Lossless compression
Many people wonder how lossless compression can be achieved.
The Huffman code takes into account the probability that levels of different magnitudes will appear, for example, the most probable values to appear frequently are assigned shorter codes and, on the other hand, the values whose probability of appearance is small are assigned they use longer code words.
If we think about it, we will realize that by replacing the signal values that will appear very frequently with shorter words, this will save us space but it does not imply any loss of quality because no information is being discarded.
If we put an example perhaps very simplified to be able to explain this method, we could imagine that we are going to compress a text. Now suppose this text contains some words that may be repeated very frequently.
For this explanation suppose that our text contains the word “statistically” many times and suppose that we substitute 3 characters for it: xx ÷.
So in each place where the word “statistically” should appear, we will replace it with the characters “xx ÷” And if this word appears enough times we will reduce the size of the text.
If we do this with each of the words that will appear several times, we will be able to make a significant reduction of the text without having to discard any information.
Therefore, when we rebuild or decompress our file, we will obtain a file exactly the same as the initial one, without any loss.
The other method where if there is a loss what is sought is to discard what is audio information the ear cannot distinguish, for example in the masking effect.
This masking what happens in our ears due to the imperfection of the human ear, supposes that two sounds do occur at approximately the same moment And these sounds have a close frequency But one of them has a much higher volume, the ear will only perceive the one who has higher volume and the one with the lowest volume will not perceive. Therefore, it can be discarded and the human ear will not perceive the difference.
This type of compression does use the technique of discarding information, which is why the resulting file has some information loss.
In general terms, today those systems that act without loss of information are being highly valued.

