
Lossy compression

Compress audio and video
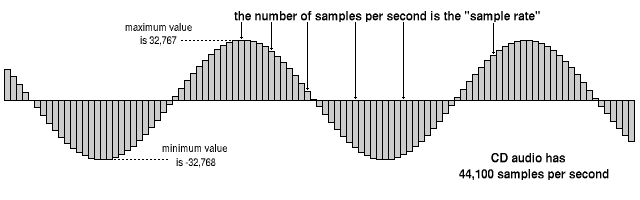
High-quality digitized audio requires a large amount of disk space. Attempts to reduce file sizes using standard cabinets do not yield significant gains due to the specificity of the audio data. However, it is possible to achieve a fairly significant level of compression of the audio information using special methods based on the analysis of the data structure and subsequent compression with some loss.
The real possibility of sound processing comparable in quality to existing analog examples appeared only in the late 1980s. In 1988, the International Organization for Standardization (ISO) formed the MPEG (Moving Pictures Expert Group) committee, whose main task is develop coding standards for moving images, sound and their combination. During the ten years of its existence, the committee has developed a series of norms on this subject. As a result, when summarizing extensive research in this area, several specific formats were recommended for storing data, differing in the quality of the results and the data flow.
Currently, there are three most common video storage standards: MPEG-1, MPEG-2, and MPEG-4. Within the first two formats, there are also formats for storing audio information: Layer-1, Layer-2 and Layer-3. These three audio formats are defined for MPEG-1 and minor extensions are used in MPEG-2. The three formats are similar to each other, but use different levels of compression and complexity compensation. Layer-1 is the simplest, it does not require significant compression costs, but it also provides a negligible compression ratio. Layer-3 level: the most time consuming and provides the best compression. Recently, this format has gained immense popularity. It is often called MP3. This name is associated with the extension of the audio files stored in this format.
Founded idea, in which all lossy audio signal compression methods – ignore the subtle details of the original sound, which are outside of that perceived by the human ear. Here several points can be highlighted.
Noise level. Sound compression is based on a simple fact: if a person is next to a loud siren, it is unlikely that he will hear the conversation of the people who are nearby. Also, this happens not because a person pays close attention to a loud sound, but to a greater extent because the human ear actually misses out sounds that are in the same frequency range as a louder sound. This effect is called masking, it changes with the difference in volume and frequency of the sound.
The second point is the division of the audio frequency band into subbands, each of which is further processed separately. The encoding program extracts the loudest sounds from each band and uses this information to determine an acceptable noise level for that band. The best encoding programs also take into account the influence of adjacent bands. A very loud sound in one band can affect the masking effect and nearby bands.
Another point of coding is the use of a psychoacoustic model based on the peculiarities of human perception of sound. Compression The use of this model is based on the removal of obviously inaudible frequencies with a more careful preservation of sounds that are clearly distinguishable by the human ear. Unfortunately, there can be no exact mathematical formulas here. Human perception of sound is a complex process that is not fully understood, so the choice of compression methods is based on analyzing listening and comparing compressed sounds differently by teams of experts. But here there are practically unlimited possibilities in the field of improving psychoacoustic models. Most of the existing algorithms to encode the human voice are based on the high predictability of said signal; Universal MPEG compression algorithms have tried to apply this technique with variable success.

