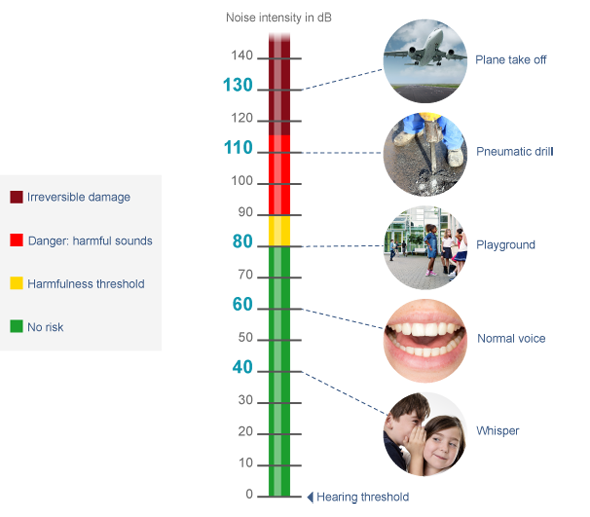
We now offer a subscription for just 10 cents a day*
You will always enjoy the full version of Mp4Gain with all its features and benefits.
For just 10 cents a day*
*Unlimited FULL version of Mp4Gain, billed $US12.50 Quarterly (+ $5 USD one time subscription payment JUST in the first payment).
All other payments will be just $3.12 per month, billed quaterly.
That's only 10 cents per day!
CLICK TO PURCHASE
THIS PRICE ONLY LASTS FOR A FEW DAYS
For just 10 cents a day*
Hoe laat je een machine luisteren om als een mens te klinken? Deel 2
Neurale netwerken (NN’s) zijn erg goed in het extraheren van abstracte representaties van gegevens en zijn daarom ideaal voor het detecteren van cognitieve eigenschappen in geluid. Laten we, om een systeem voor dit doel te bouwen, eerst onderzoeken hoe geluid wordt gerepresenteerd in het menselijk gehoororgaan, dat we kunnen gebruiken om neurale netwerken te motiveren om representaties van klankbetekenis te verwerken.

cochleaire representatie
Het menselijk gehoor begint met het uitwendige oor, dat eerst uit het atrium bestaat. De oortelefoon fungeert als een vorm van geluidsspectrale voorbewerking, waarbij het ingangsgeluid wordt aangepast op basis van de oriëntatie ten opzichte van de luisteraar. Het geluid komt dan de gehoorgang binnen via een opening in het atrium en wijzigt vervolgens de spectrale kenmerken van het binnenkomende geluid door deze versterkte frequentie te resoneren (variërend van ~1-6 kHz) [1].
Hoe een machine te laten luisteren als een mens?
Illustratie van het menselijk gehoorsysteem
Wanneer de geluidsgolven het einde van de gehoorgang bereiken, prikkelen ze het trommelvlies, waaraan de gehoorbeentjes (de kleinste botten in het menselijk lichaam) zijn bevestigd. Deze botten brengen druk van de gehoorgang over naar het met vocht gevulde slakkenhuis van het binnenoor [1]. Het slakkenhuis speelt een belangrijke rol bij het begeleiden van de weergave van de betekenis van geluid voor neurale netwerken (NN), aangezien dit het orgaan is dat verantwoordelijk is voor het vertalen van akoestische trillingen in menselijke neurale activiteit.
Het is een opgerolde buis die over de lengte wordt gescheiden door twee membranen, het membraan van Reisner en het basaalmembraan. In het slakkenhuis bevindt zich een rij van ongeveer 3.500 binnenste haarcellen [1]. Wanneer de druk het slakkenhuis binnenkomt, worden de twee membranen ingedrukt. Het basaalmembraan is smaller en stijver aan de basis, maar breder en losser aan de top, waardoor de respons op een bepaalde frequentie op elke plaats langs de lengte sterker is.
In eenvoudige bewoordingen kan het basilaire membraan worden gezien als een reeks continue banddoorlaatfilters van membraanlengte die geluiden scheiden in hun spectrale componenten.
Hoe een machine te laten luisteren als een mens?
Illustratie van het menselijke slakkenhuis
Dit is het meest fundamentele mechanisme waarmee mensen geluidsdruk omzetten in neurale activiteit. Daarom is het redelijk om aan te nemen dat de spectrale representatie van geluid voordelig is bij het bouwen van modellen van geluidsperceptie met kunstmatige intelligentie. Omdat de frequentierespons in het basilair membraan exponentieel varieert, is een logaritmische weergave van de frequentie waarschijnlijk het meest efficiënt. Een dergelijke frequentierepresentatie kan worden gegenereerd met behulp van een filterbank van gammatonen. Deze filters worden vaak gebruikt bij het modelleren van spectrale filtering van het auditieve systeem, omdat ze de impulsrespons kunnen schatten van menselijke auditieve filters die voortkomen uit gehoorzenuwvezels als reactie op een soort witte ruis die de “revcor” -functie wordt genoemd.
Hoe een machine te laten luisteren als een mens?
Vergelijking van vereenvoudigde transductie van menselijk profiel en gedigitaliseerde profieltransductie
Het slakkenhuis heeft ongeveer 3.500 binnenste haarcellen en mensen kunnen hiaten in geluiden detecteren van 2 tot 5 ms lang, dus spectrale ontleding met behulp van 3.500 gammatoonfilters verdeeld in vensters van 2 ms lijkt een machine om te bereiken. beste parameter om weer te geven. In real-world scenario’s geloof ik echter dat minder spectrale decompositie ook gewenste resultaten oplevert in de meeste analyse- en verwerkingstaken, terwijl het rekenkundig beter haalbaar is.
Verschillende softwarebibliotheken voor auditieve analyse zijn online beschikbaar. Een belangrijk voorbeeld is de Gammatone Filterbank Toolkit van Jason Heeris, die niet alleen afstembare filters biedt, maar ook tools biedt voor spectrale analyse van geluidssignalen met behulp van gammatoonfilters.
neurale codering
Terwijl neurale activiteit zich verplaatst van het slakkenhuis naar de gehoorzenuw en oplopende gehoorpaden, vinden er verschillende processen plaats in de hersenstamkernen voordat het de auditieve cortex bereikt.
Deze procedures bouwen een neurale code die de interactie tussen de stimulus en de perceptie vertegenwoordigt. Veel meer over de specifieke taken binnen deze kernels zijn nog steeds gissen of onbekend, dus ik zal op een hoog niveau bespreken hoe ze werken.